介绍
什么是 Feast?
Feast 是一个 开源 特征商店,通过允许团队定义、管理、验证并将特征服务于生产中的模型,帮助团队大规模运行机器学习系统。
下图显示了 Feast 的架构
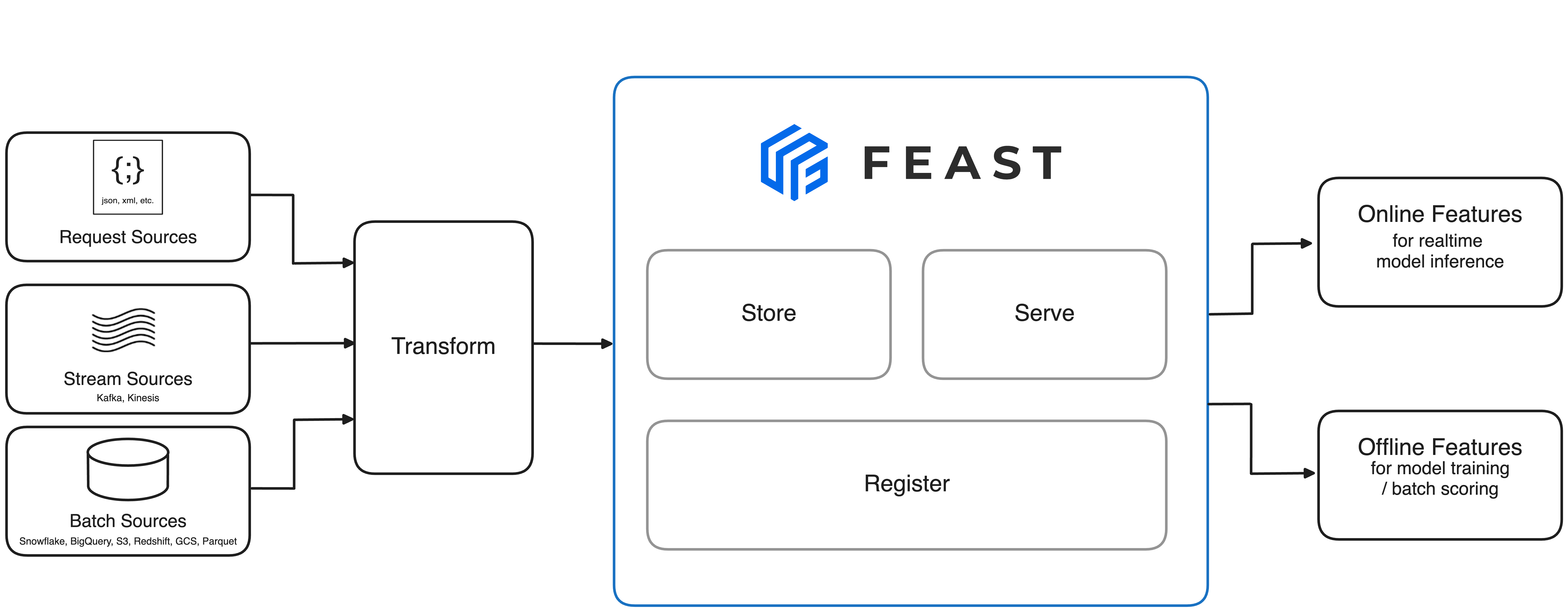
Feast 提供以下功能
加载流式、批处理和请求时数据: Feast 构建的目的是能够从各种有界或无界来源摄取数据。Feast 允许用户从 API 调用、流、对象存储、数据库或笔记本中摄取数据。摄取到 Feast 中的数据可以持久化到在线存储和历史存储中,这些存储用于创建训练数据集并将特征服务于在线系统。
标准化定义: Feast 成为组织内所有特征定义和数据的唯一事实来源。团队能够捕获特征的文档、元数据和指标。这使得团队能够清晰地沟通特征,测试特征数据,并确定特征对其用例是否安全且相关。
历史服务: 持久化在 Feast 中的特征可以通过其特征服务 API 获取,以生成训练数据集。Feast 能够生成庞大的训练数据集,这些数据集与最初摄取数据的来源无关。Feast 还能够在连接这些数据源时确保时间点正确性,这反过来又确保了特征到达模型的质量和一致性。
在线服务: Feast 为已摄取到系统中的所有数据暴露低延迟服务 API。这使得所有生产 ML 系统在查找实时特征时,都可以使用 Feast 作为主要数据源。
训练和服务之间的一致性: Feast 通过统一的摄取层、统一的服务 API 和规范的特征引用,提供了一致的特征数据视图。通过在特征引用上构建 ML 系统,团队抽象了底层数据基础设施,使得在训练和服务之间安全地移动模型成为可能,而不会降低数据一致性。
特征共享和重用: Feast 提供了发现和元数据 API,允许团队跟踪、共享和重用跨项目的特征。Feast 还提供了一个轻量级 Web UI 来暴露这些元数据。Feast 还将创建特征的过程与消耗过程解耦,这意味着启动新项目的团队可以简单地消耗商店中已存在的特征,而不是从头开始。
统计和验证: Feast 允许生成基于系统中特征的统计信息。Feast 与 TFDV 兼容,这意味着 Feast 生成的统计信息可以使用 TFDV 进行验证。Feast 还允许团队将 TFDV 模式捕获为特征定义的一部分,允许领域专家定义数据属性,这些属性可用于在其他生产环境(如训练、摄取或服务)中验证这些特征。
什么是特征商店?
特征商店是帮助 ML 团队在将特征投入生产时减少所面临挑战的系统。
特征商店帮助解决的一些主要挑战包括
特征共享和重用: 特征工程是构建端到端 ML 系统中最耗时的活动之一,但许多团队仍在孤岛中开发特征。这导致跨团队和项目进行了大量重复开发和重复工作。
大规模服务特征: 模型需要来自各种来源的数据,包括 API 调用、事件流、数据湖、数据仓库或笔记本。ML 团队需要能够以高性能和可靠的方式将所有这些数据源存储和服务于其模型。挑战在于可伸缩地生产用于模型训练的大量特征数据集,并在服务中以低延迟和高吞吐量提供对实时特征数据的访问。
训练和服务之间的一致性: 数据科学家和工程团队之间的分离通常导致在从训练转移到在线服务时重新开发特征转换。由于训练和服务实现之间的差异引起的不一致性经常导致模型在生产中的性能下降。
时间点正确性: 通用数据系统并非针对 ML 用例构建,因此无法提供时间点正确的特征数据查找。如果无法获得时间点正确的数据视图,则模型会在与生产中发现的数据不具代表性的数据集上进行训练,导致准确性下降。
数据质量和验证: 特征是 ML 系统业务关键输入。团队需要对生产中提供的数据质量充满信心,并且需要在基础数据发生任何漂移时能够做出反应。
如何在 Kubeflow 中使用 Feast?
Feast 可以与 Kubeflow 在同一个 Kubernetes 集群上运行,并可用于为在 Kubeflow Pipelines 中训练并通过 KServe 部署的模型提供特征服务。
要求
- 安装了 Kubeflow 的 Kubernetes 集群
- 用于作为 离线存储 的数据库 (BigQuery, Snowflake, Redshift 等)
- 用于作为 在线存储 的数据库 (Redis, Datastore, DynamoDB 等)
- 用于作为 特征注册表 的存储桶 (S3, GCS, Minio 等) 或 SQL 数据库 (Postgres, MySQL 等)
- 用于 物化数据 并运行其他 Feast 作业的工作流引擎 (Airflow, Kubeflow Pipelines 等)
安装
要将 Feast 与 Kubeflow 一起使用,请按照以下步骤操作
请参阅他们的 生产使用 指南,了解在生产中运行 Feast 的最佳实践。
使用 Feast API
一旦 Feast 与 Kubeflow 安装在同一个 Kubernetes 集群中,用户无需任何额外步骤即可直接访问其 API。
Feast 提供以下类别的 API
- 特征定义和管理:
- Feast 提供了 Python SDK 和 CLI 用于与 Feast Core 交互。
- Feast Core 允许用户定义和注册特征和实体及其相关的元数据和模式。
- Python SDK 通常由最终用户在 Jupyter Notebook 中使用来管理 Feast,但 ML 团队可以选择对特征规范进行版本控制,以遵循基于 GitOps 的方法。
- 模型训练:
- Feast Python SDK 可用于触发 训练数据集的创建。
- 使用此 SDK 的最自然之处是作为 Kubeflow Pipeline 的一部分创建训练数据集,然后在进行模型训练。
- 模型服务:
请参阅 Feast 的 教程页面,了解更多有关使用 Feast 的信息。