Kubeflow Spark Operator 基准测试
概述
随着组织越来越多地采用 Kubernetes 进行大规模数据处理,在 Kubernetes 上高效执行 Apache Spark 工作负载已成为一项关键需求。 Kubeflow Spark Operator 简化了 Kubernetes 内的 Spark Job 提交和管理,但其处理涉及数千个 Job 提交和数万个 Pod 的高并发工作负载的能力需要全面验证。为了评估 operator 当前的性能,我们开发了基准测试脚本并使用 Kubeflow Spark Operator 进行了测试。这些测试是可重复的,使用户能够利用此基准测试工具包来评估未来发布的版本以及引入的性能优化。
基准测试对于确定 Spark Operator 在高负载下(特别是处理数千个并发 Job 提交和有限资源分配时)的性能至关重要。主要目标包括:
- 识别控制器处理 SparkApplication CR 中的瓶颈。
- 优化 Spark Operator 控制器 Pod 的资源分配。
- 评估单个 operator 实例是否足够,或者是否需要多个实例来增强性能。
- 确定 Kubernetes Job 调度、API 响应能力和资源管理中的瓶颈。
本指南提供了 Kubeflow Spark Operator 基准测试的详细框架,适用于任何 Kubernetes 集群。虽然此处介绍的配置和结果基于 Amazon EKS,但该方法灵活,可应用于其他云提供商或本地 Kubernetes 环境。
注意
这些基准测试侧重于评估 Spark Operator 的性能,而非 Spark 作业本身。为了隔离 operator 管理高 Job 提交率和 Pod 启动的能力,为 Driver 和 Executor Pod 分配了最小资源。这种方法减少了所需节点数量,从而能够清晰评估 operator 在高并发下调度和启动 Job 的效率。Spark Operator 的工作原理
Kubeflow Spark Operator 通过引入 SparkApplication 自定义资源定义 (CRD) 来扩展 Kubernetes,该 CRD 定义了 Spark 作业配置,例如驱动程序和执行程序 Pod 规范、依赖项和运行时参数。一个控制器(部署为 Pod 并通过 Helm 管理)通过协调循环来监督这些 CRD,该循环包括:通过 API 将 SparkApplication 对象转换为 Kubernetes Pod 来提交作业;通过跟踪状态(例如,Pending、Running、Completed、Failed)和更新状态来管理其生命周期;与 Kubernetes 调度器协调调度资源(可选地使用 Webhooks 进行验证);以及通过终止已完成或失败的作业进行清理,除非明确禁用。
该 Operator 基于 controller-runtime 库构建,通过每个实例一个工作队列来处理提交。每个控制器实例独立运行,拥有自己的队列,性能取决于 CPU 可用性、每次提交生成的 JVM 进程所需的内存以及 Kubernetes API 的响应速度。
Helm Values 中可用的调优参数
Spark Operator 的 Helm chart 提供了几个参数来调优 Spark Operator 的性能。
- controller.workers: 设置协调器线程的数量 (`default: 10`)。增加此值(例如,到 20 或 30)可增强并发性,如果 CPU 资源允许,可能会提高吞吐量,尽管 API 延迟可能会限制收益。
- workqueueRateLimiter:
- bucketQPS (default:
50): 这限制了队列处理作业的平均速率(每秒项目数)。增加它可能看起来会加快速度,但如果 Operator 的控制器 Pod 已经达到其 CPU 的最大利用率或正在等待 Kubernetes API 服务器,队列处理速度就不会加快。 - bucketSize (default:
500): 这设置了可以排队的作业的最大数量。提高它允许在突发期间堆积更多作业,但如果处理速率没有增加,那些额外的作业只会等待更长时间。 - maxDelay.enable 和 maxDelay.duration (default:
true, 6h): 管理溢出行为。缩短持续时间(例如,到 1h)可能会加速重新排队,但如果队列保持满载,则存在事件丢失的风险。
- bucketQPS (default:
- webhook.enable: 切换 Webhook 使用 (`default: true`)。禁用此选项 (`false`) 会降低延迟(每个作业约 60 秒),但需要利用 Spark Pod Templates 功能。
- batchScheduler.enable: 启用批处理调度器,如 Volcano 或 Yunikorn (`default: false`)。设置为 true 可以优化大规模工作负载的 Pod 调度。
- 控制器资源: 定义控制器 Pod 的 CPU/内存请求和限制 (`default: unset`)。分配更多资源(例如,64 vCPU,20Gi)支持更高的并发性。
基础设施设置
1. 集群配置
- Kubernetes 集群: 在 Amazon EKS 1.31 (eks.19) 上测试,可适应任何 Kubernetes 环境。
- 网络:
- 两个子网: 部署到
100.64.128.0/171和100.64.0.0/17子网(每个 32766 个 IP 地址),分布在一个带有两个附加 CIDR 的 VPC 的两个可用区中。Spark 作业目标是在单个 AZ 中运行。
- 两个子网: 部署到
- 节点配置:
- 用于 Spark Pod 的专用节点组: 优化 Pod 填充效率以最小化成本,使用
200个m6a.4xlarge节点(每个 16 vCPU,64 GB RAM)。默认 Pod 容量为每个节点 110 个,通过 kubelet 设置 (`maxPods`) 增加到 220 个,以处理更多 Spark Pod,每个 Pod 消耗一个 IP 地址。 - 用于 Spark Operator 的专用节点组: 确保 Spark Operator 在计算密集型 c5.9xlarge 实例上隔离运行,防止其他工作负载干扰。这种方法遵循系统关键组件的最佳实践,降低了驱逐或资源争用的风险。
- Spark Operator 控制器和 Webhook Pod 资源: 为控制器 Pod 请求了
33 vCPUs和50 Gi内存,为 webhook Pod 请求了1vCPU和10Gi内存,这些配置是为基准测试量身定制的。 - 用于 Prometheus 的专用节点组: 用于使用 Kube Prometheus Stack 捕获和监控指标,该堆栈包括用于可视化的 Prometheus 和 Grafana。在大规模运行时,Prometheus 会消耗大量 CPU 和内存,因此将其运行在专用节点上可确保它不会与 Spark Pod 竞争。通常使用节点选择器或污点专门为监控组件(Prometheus、Grafana 等)分配一个节点或节点池。
- 用于 Spark Pod 的专用节点组: 优化 Pod 填充效率以最小化成本,使用
警告
配置 200 个节点可能成本高昂(例如,EKS 上每个节点约 0.6912 美元)。用户在复制前应评估费用。2. 工作负载配置
- 软件版本:
- Spark Operator 版本: 最新稳定版本(例如,
v2.1.0)。 - Spark 版本:
Apache Spark 3.5.3(与 Operator 兼容)。
- Spark Operator 版本: 最新稳定版本(例如,
- 作业类型: 计算 Pi 的 Spark 作业,包含 1 小时的睡眠间隔以模拟固定运行时长。
- 并发: 作业并发提交以模拟高并发工作负载。关键细节包括:
- 总应用数:
6000个 Spark 应用。 - 每个虚拟用户的应用数: 每个用户
2000个应用,共有三个虚拟用户使用 Locust 负载测试工具提交作业。 - 提交速率: 作业以每分钟
1000个应用的速度提交到 Kubernetes 集群。 - 提交窗口: 所有
6000个作业在 6 分钟内提交,其余时间由 Spark Operator 处理和管理工作负载。 - 总 Pod 数: 每个 Spark 作业由
1个驱动程序 Pod 和5个执行程序 Pod 组成,总共 6 个 Pod,在6000个应用中产生36000个 Pod,由配置有200个节点的集群支持,以确保有足够的资源进行执行。
- 总应用数:
3. 要测量的指标
为了有效评估 Kubeflow Spark Operator 在高并发工作负载下的性能,我们作为此基准测试的一部分,开发了一个新的自定义 Grafana 面板(Spark-Operator Scale Test Dashboard)。该面板是开源且免费提供的,允许您在自己的环境中监控 Spark Operator 和 Kubernetes 指标。下面,我们概述了该面板跟踪的关键指标,这些指标分为三个主要领域:Spark Operator Pod 指标、Spark 应用指标和 Kubernetes 指标。这些指标提供了资源使用、作业处理效率和集群健康的全面视图。
Spark Operator Pod 指标
- 最大 CPU 使用率: 跟踪控制器 Pod 的最高 CPU 消耗,帮助您确定其在高负载下是否受 CPU 限制。
- 最大内存使用率: 监控峰值内存使用情况,确保 Pod 有足够的内存进行作业处理。
- 网络发送字节数: 跟踪控制器 Pod 发送的数据量,有助于发现网络瓶颈。
- 网络接收字节数: 监控传入数据,评估网络延迟是否影响性能。
- 工作队列深度: 衡量队列中待处理的 SparkApplication 提交数量,指示 Operator 是否能跟上接收到的作业。例如,
workqueue_depth{container="spark-operator-controller"}。 - 工作队列总添加数: 随时间计算添加到工作队列中的作业总数,反映工作负载的强度。
- 工作队列持续时间(秒): 衡量作业在处理前在队列中等待的时长,突出潜在的延迟。
- 工作持续时间(秒): 跟踪处理每个作业所需的时间,显示 Operator 协调循环的效率。
- 工作队列总重试次数: 计算作业重试次数,指示作业提交或 Pod 创建存在问题。
- 最长运行控制器线程(秒): 衡量单个协调器线程的最大持续时间,有助于检测缓慢或卡住的操作。
- 未完成工作: 跟踪仍在进行中的作业,确保所有提交最终都能完成。
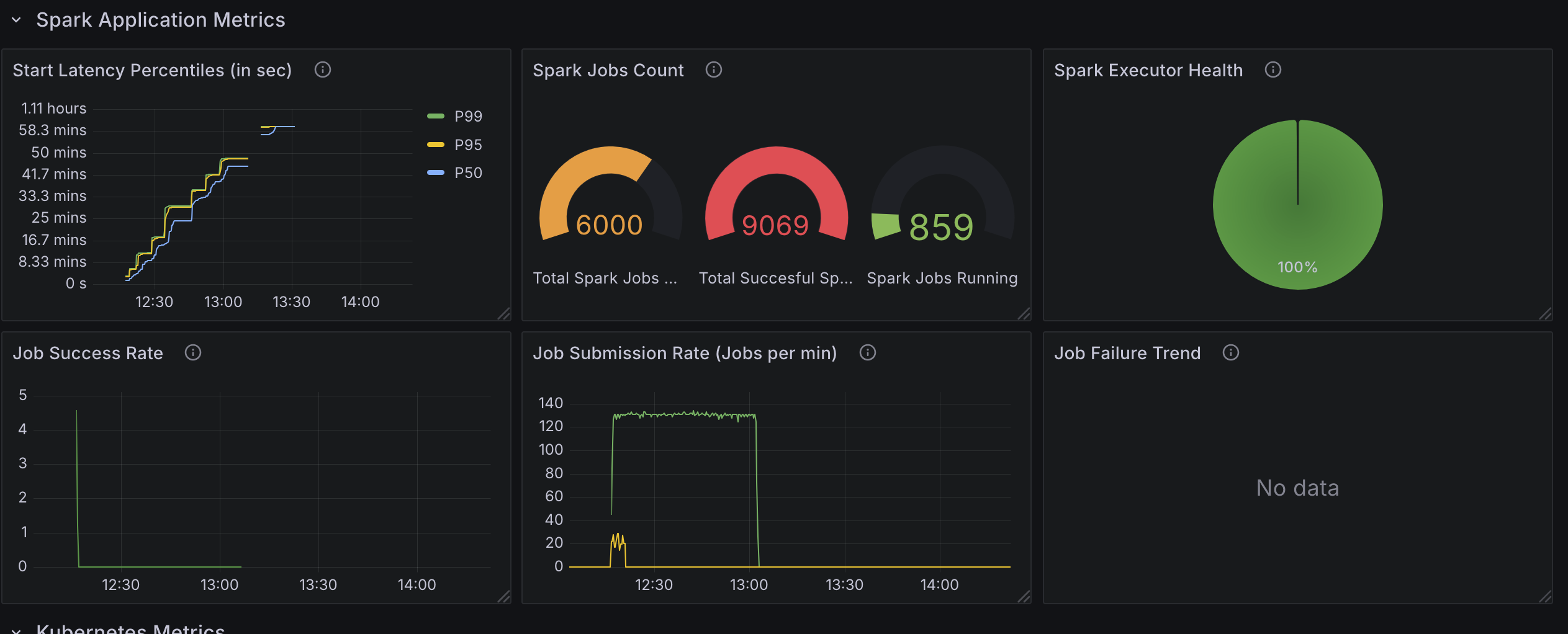
Spark 应用指标
- 启动延迟百分位数(秒): 衡量从作业提交到执行开始的时间,使用百分位数(例如,
p50、p90、p99)来显示延迟分布。 - Spark 作业计数: 跟踪已提交、正在运行和已完成的 Spark 作业总数,提供工作负载进度的快照。
- 作业提交速率(每分钟作业数): 监控作业提交速率,确保其与预期的并发级别匹配。
- 作业成功率: 计算成功完成的作业百分比,有助于识别故障或错误。
- 作业失败趋势: 随时间跟踪作业失败情况,使您能够发现不稳定或资源争用时期。
Kubernetes 指标
- API Server 延迟 (p90): 衡量 API Server 请求的第 90 个百分位数延迟,指示 API 响应可能存在的延迟。
- API Server 请求持续时间(秒): 跟踪 API 请求的总持续时间,帮助查明缓慢的操作。
- 准入 Webhook 准入持续时间(秒): 监控准入 Webhook 所花费的时间,如果启用,这会减慢 Pod 创建速度。
- Etcd 延迟 (p99): 衡量 etcd 操作的第 99 个百分位数延迟,对于理解负载下的数据库性能至关重要。
- API Server 数据库总大小: 跟踪 etcd 数据库的大小,确保其保持可管理且不会降低性能。
- Spark Application 对象计数: 计算集群中 SparkApplication 自定义资源 (CR) 的数量,反映工作负载规模。
- 节点对象计数: 监控节点数量,验证集群是否为工作负载进行了适当扩展。
- Pod 对象计数: 跟踪 Pod 总数,确保集群能够支持预期的数量(例如,最多 36000 个 Pod)。
如何运行基准测试
测试设置
基准测试工具: Locust 用于模拟并发作业提交并测量性能指标。Locust 脚本动态生成 SparkApplication YAML 文件并提交到 Kubernetes 集群。
- 动态作业命名: 每个作业都使用
uuid.uuid4()分配一个唯一名称。 - 速率限制: 作业以受控速率提交(例如,每秒 1 个作业)。
- 作业状态监控: 脚本监控已提交作业的状态,以确保它们按预期运行。
- 清理: 测试结束后会删除作业,除非设置了
--no-delete-jobs标志。
Locust 脚本配置: 以下参数在 Locust 脚本中可用。
- 用户 (-u): Locust 脚本的并发虚拟用户数量。
- 每分钟作业数 (–jobs-per-min): 控制作业提交速率。
- 作业限制 (–job-limit-per-user): 每个用户提交的最大作业数量。
- 命名空间 (–spark-namespaces): 作业提交到指定的命名空间。
- Spark 作业模板 (–spark_job_template): SparkApplication YAML 模板的路径。
- 删除作业 (–no-delete-jobs): 如果设置,测试后不会删除作业(对调试有用)。
基准测试过程使用 Locust,它创建用户进程,根据 locustfile.py 文件中的配置执行任务。这使我们能够以受控速率生成和提交 SparkApplication CRD,从而能够在大规模下测量性能。
安装
基准测试工具包和脚本可在 Data on EKS GitHub 仓库中找到。
首先,在虚拟环境中安装 Locust 及其依赖项。
python3.12 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
运行 Locust
对于此基准测试,我们预先创建了三个 Spark 作业命名空间 spark-team-a、spark-team-b 和 spark-team-c,以便在它们之间均匀分布工作负载。这些命名空间在 Spark Operator 的 Helm values 中 controller.spark.jobNamespaces 下配置,确保 Operator 只监控这些命名空间以进行作业提交。以下命令在无头模式下运行 Locust,以每分钟 1000 个作业的速率在这些命名空间中提交 6000 个作业。
locust --headless --only-summary -u 3 -r 1 \
--job-limit 2000 \
--jobs-per-min 1000 \
--spark-namespaces spark-team-a,spark-team-b,spark-team-c
基准测试结果
为了评估 Kubeflow Spark Operator 在高并发工作负载下的性能,我们进行了两项关键测试:一项启用了 webhook,另一项禁用了 webhook。这些测试涉及提交 6000 个 Spark 应用,每个应用包含 1 个驱动程序和 5 个执行程序 Pod,总共 36000 个 Pod,以每分钟 1000 个作业的速率跨越三个命名空间。下面,我们将详细介绍测试配置、观察结果和关键发现,以清晰结构化的方式呈现,以突出 Operator 的行为和限制。
测试 1:6000 个 Spark Applications(启用 Webhook)
测试配置
- Spark Operator 控制器 Pod:
- 实例类型:
c5.9xlarge - 资源:
36个 vCPU,72GB 内存。 - 部署: 使用默认值部署的 Helm chart。
- 控制器线程:
10个线程。 - Operator 使用默认的 helm 配置部署,但
metrics-job-start-latency-buckets除外,因为默认的最大桶大小 500 太小,无法有效地测量作业启动时间。请参阅 PR。
- 实例类型:
- Spark 应用 Pods:
- 节点数量:
200 - 实例类型:
m6a.4xlarge - 资源: 每个节点
16个 vCPU,64GB 内存。 - 驱动程序和执行程序: 每个应用 1 个驱动程序 Pod 和 5 个执行程序 Pod。
- 作业行为: 执行程序主要通过睡眠来模拟最小资源使用。
- 节点数量:
- 工作负载:
- 作业类型: 简单的 Spark 作业,具有固定运行时长(大部分时间处于睡眠状态)。
- 总作业数: 在三个命名空间(
spark-team-a、spark-team-b、spark-team-c)中共 6000 个作业,提交速率为每分钟1000 job。 - 此测试受 CPU 限制,并确保跨多个命名空间具有一致的负载,以模拟实际使用场景。
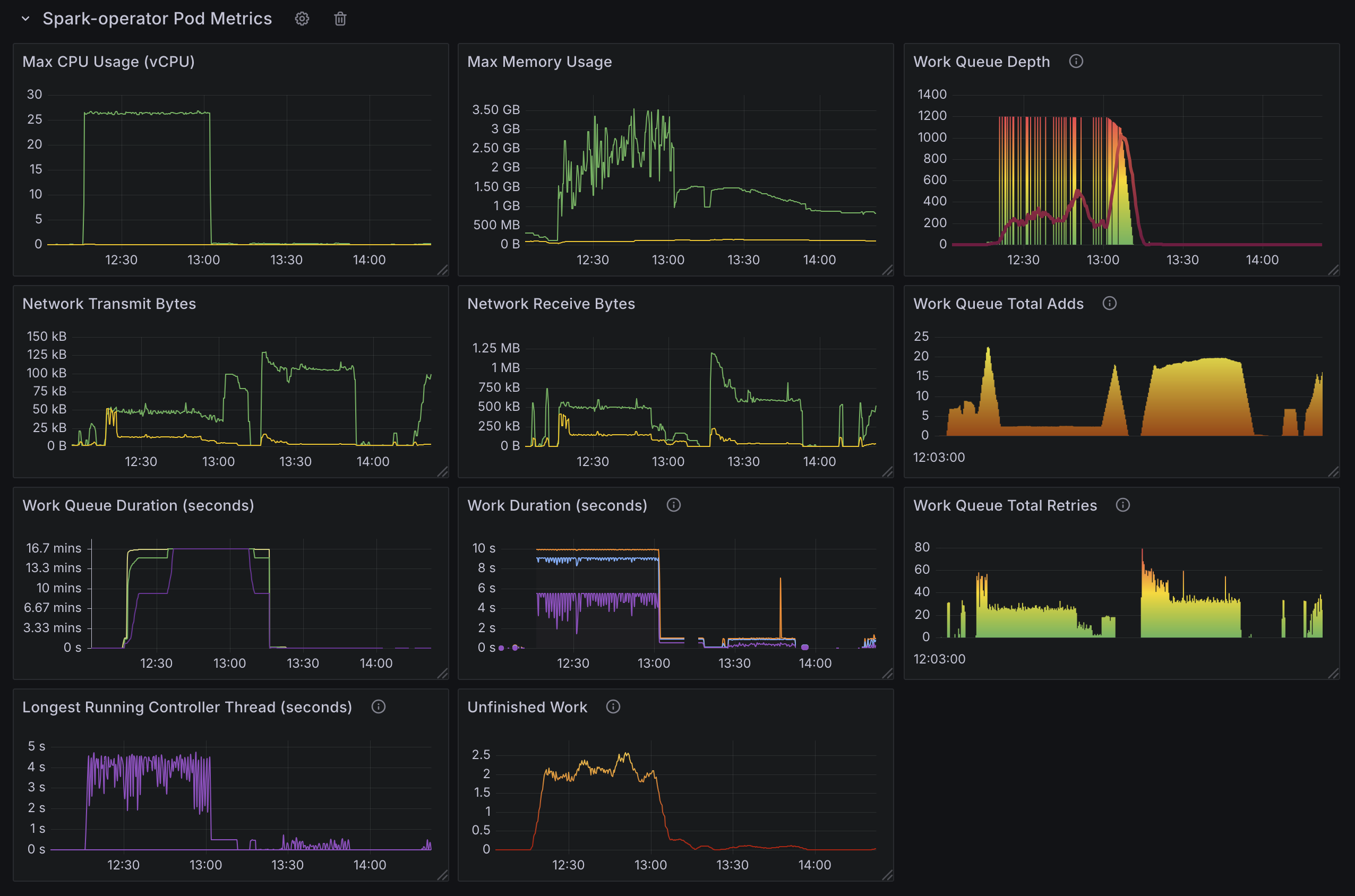
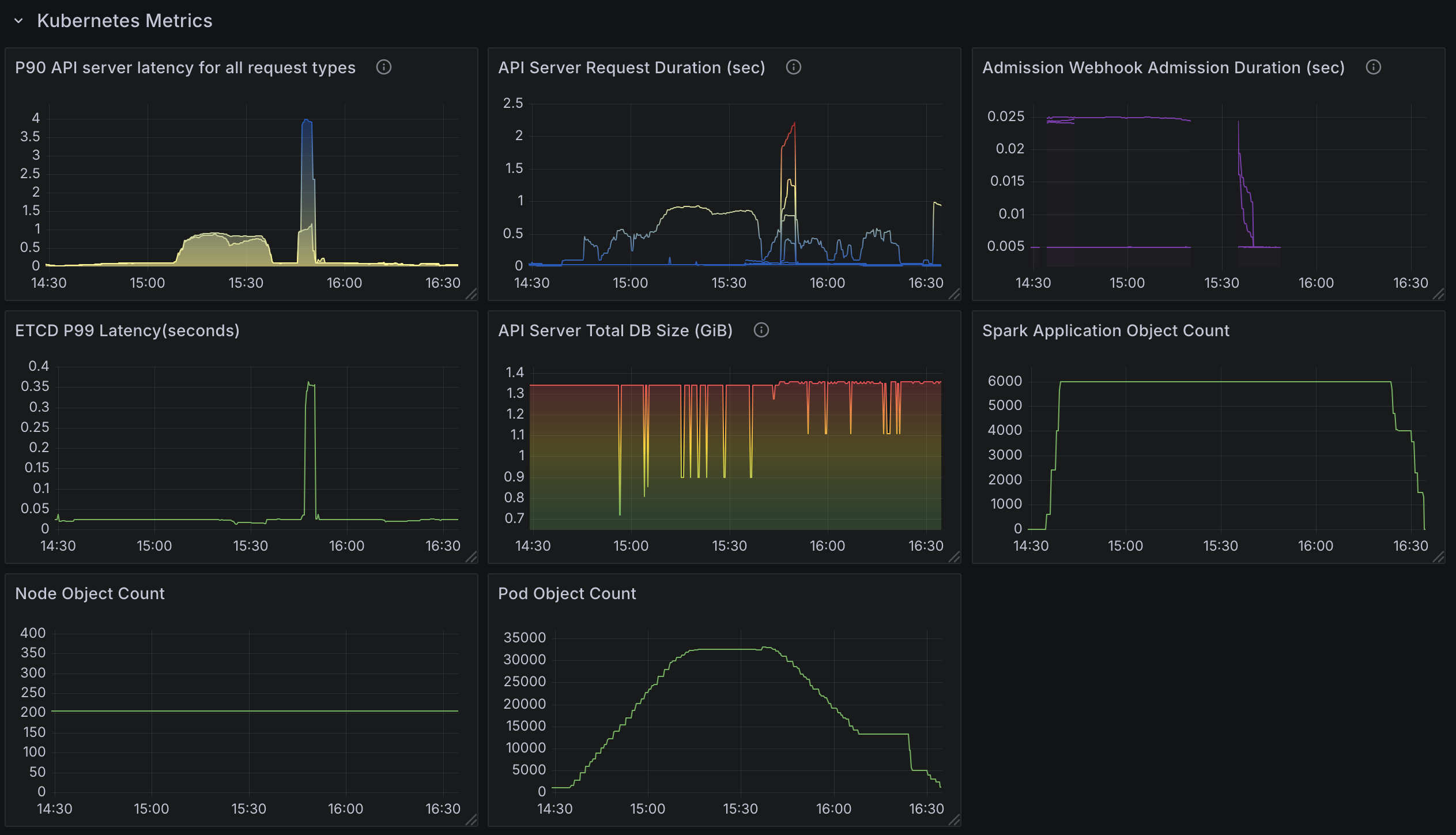
Spark Operator 规模测试的观察结果
- CPU 利用率:
- Spark Operator 控制器 Pod 受 CPU 限制,在峰值处理期间利用所有
36 cores。 - CPU 限制了作业处理速度,使得计算能力成为可伸缩性的关键因素。
- Spark Operator 的吞吐量(由
spark_application_submit_count metric指标指示)仅受 CPU 单核速度、可用核心数量和配置的 goroutine 数量 (`20`) 的影响。 - 在
36 core机器上将 goroutine 从10增加到20使作业提交速率从~130-140提高到~140-155个作业每分钟(增长~7-11%),但收益递减,这可能是由于 Spark Operator 队列处理瓶颈所致。
- Spark Operator 控制器 Pod 受 CPU 限制,在峰值处理期间利用所有
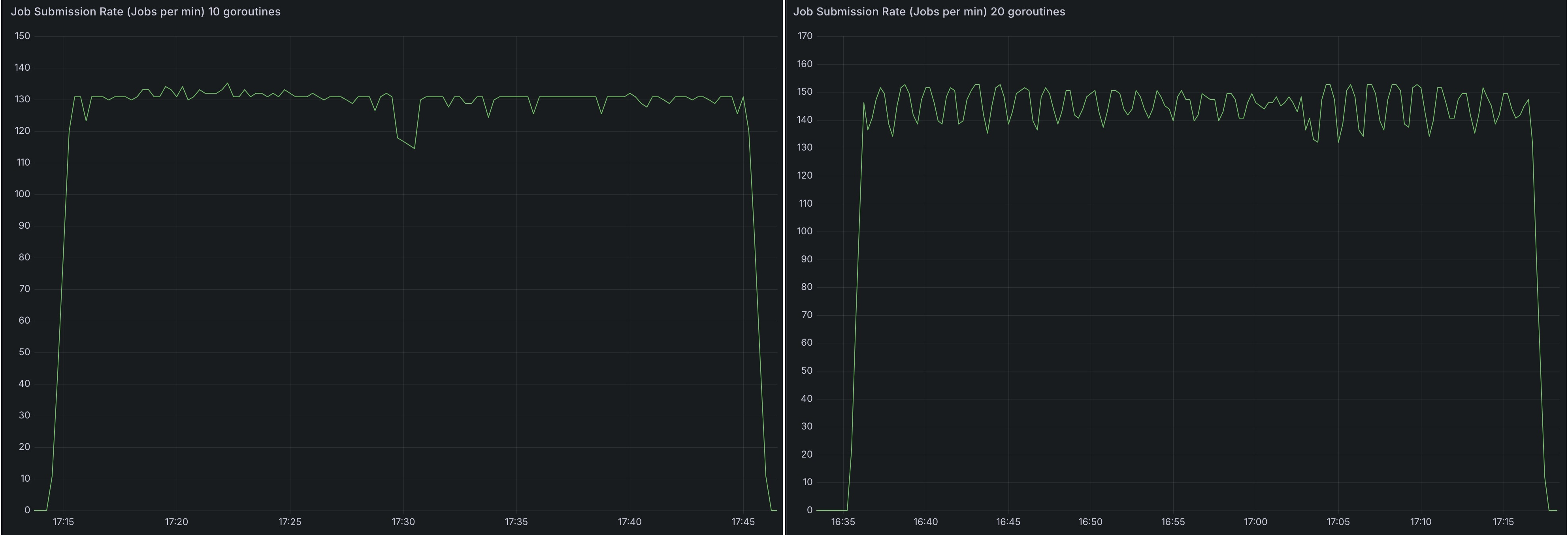
- 提交到集群的应用数量不影响处理速度。
2000个应用和6000个应用之间没有差异。 - 内存占用不随提交的应用数量变化。然而,它会随着 goroutine 数量的增加而增加。
- 内存消耗保持稳定,无论处理的应用数量多少。
- 这表明内存不是瓶颈,增加 RAM 不会提高性能。
- 作业处理速率:
- Spark Operator 以每分钟
~130个应用的速度处理应用。 - 处理速率受 CPU 限制的上限,如果没有额外的计算资源,无法进一步扩展。
- 由于 Operator 每分钟只能处理
130-150个应用,后提交的 Spark 作业的驱动程序 Pod 大约需要~1小时才能启动。
- Spark Operator 以每分钟
- 作业处理时间:
- 处理
2000个应用需要~15分钟。 - 处理
4000个应用需要~30分钟。 - 这些数字与观察到的每分钟 130 个应用的处理速率一致。
- 由于 Spark Operator 忙于处理新应用,已提交的 Spark 应用的状态更新很慢。一些应用的状态更新需要
~30分钟。
- 处理
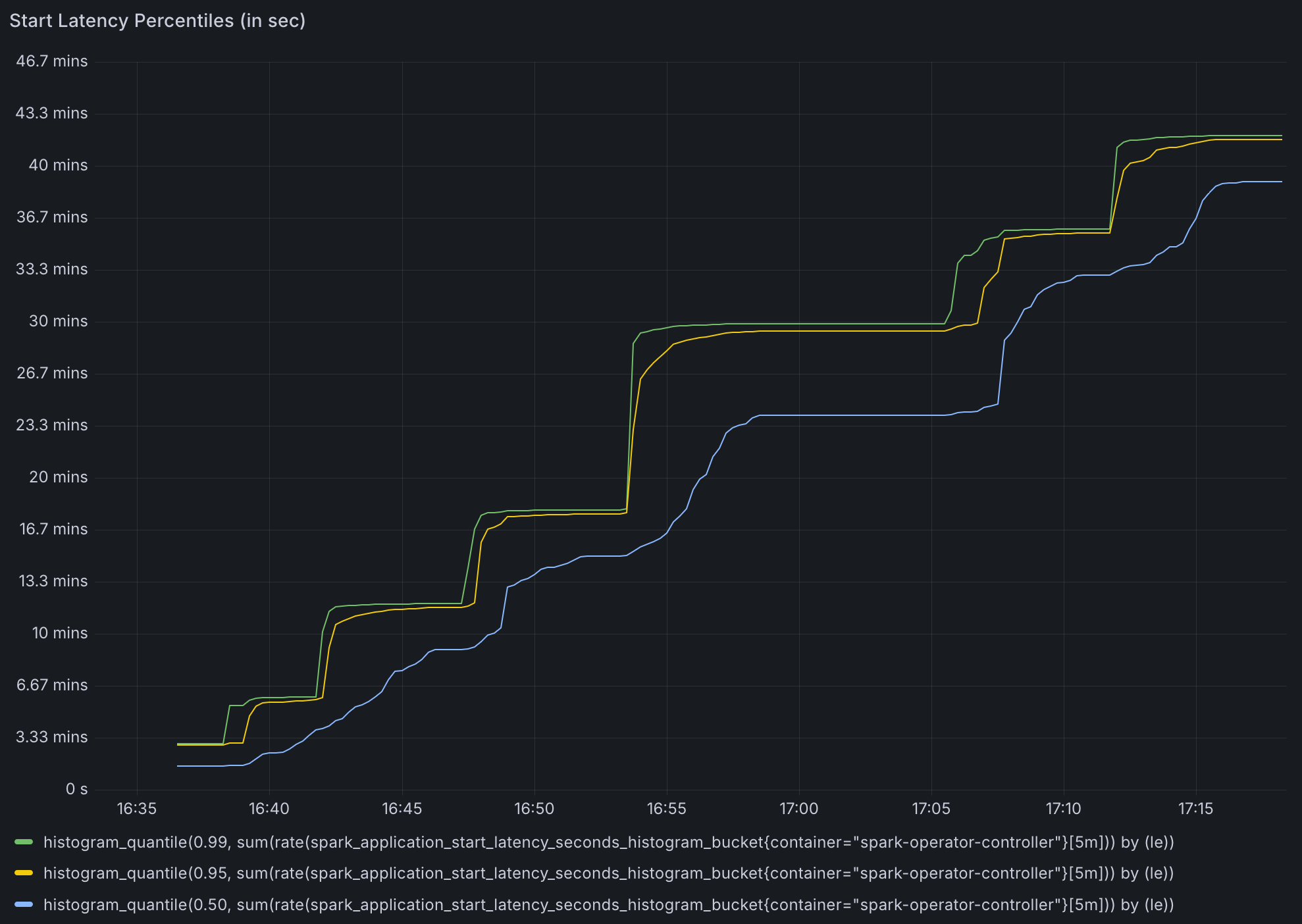
- 工作队列持续时间指标可靠性:
- 默认的工作队列持续时间指标一旦超过
16分钟就会变得不可靠。- Spark Operator 的
metrics-job-start-latency-buckets选项的默认配置的最大桶大小为300s,我们在测试中增加了桶,但该指标未记录超过 300s 的延迟。
- Spark Operator 的
- 在高并发下,此指标无法准确反映队列处理时间。
- 默认的工作队列持续时间指标一旦超过
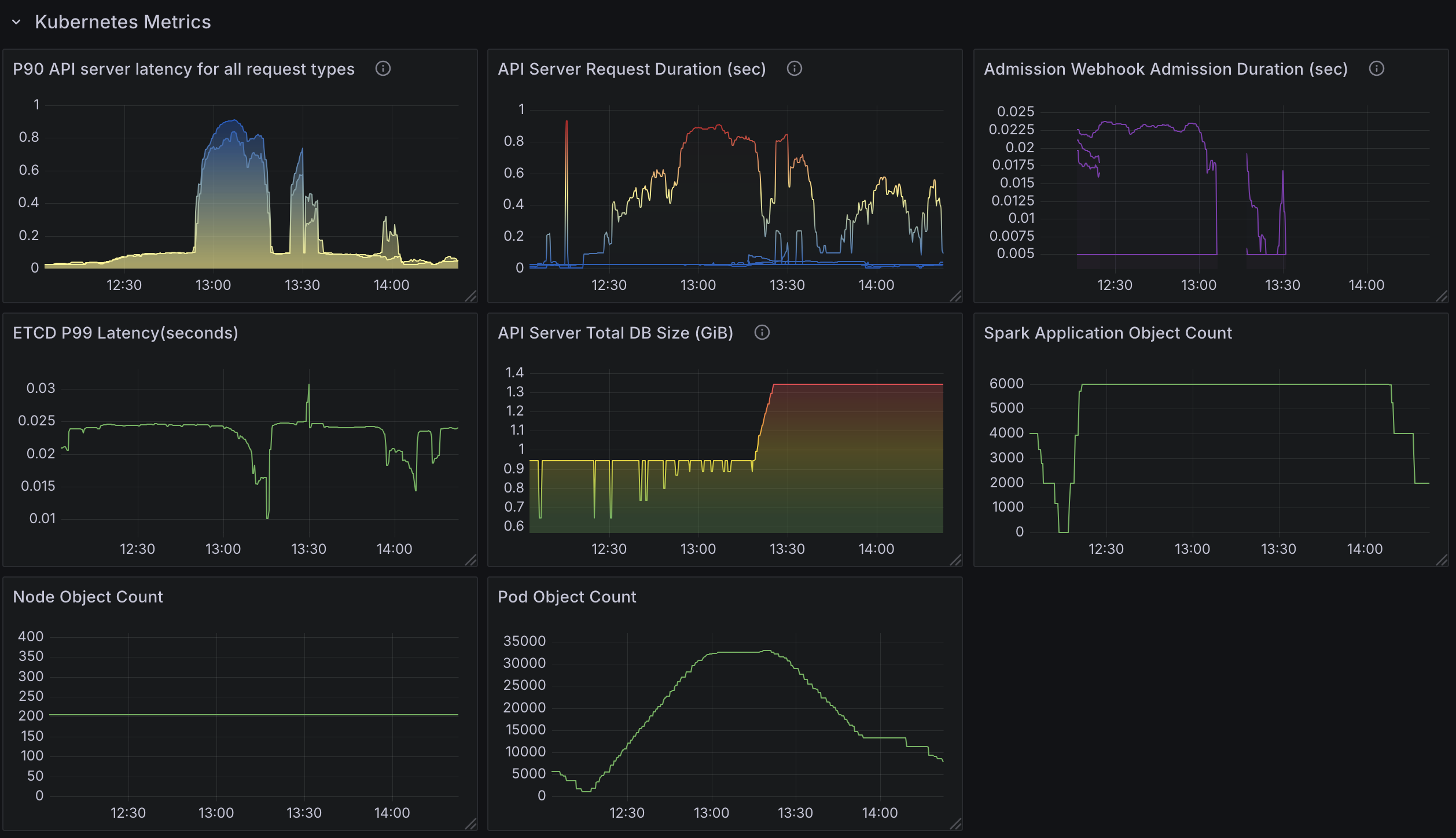
- API Server 性能影响:
- 在高工作负载条件下,Kubernetes API 请求持续时间显著增加。
LIST调用持续出现显著延迟。这并非由 Operator 引起,而是由 Spark 在其自身的命名空间中列出 Pods 以查找执行程序 Pods 引起的。- 这是由于 Spark 频繁查询执行程序 Pods 引起的,而不是 Spark Operator 本身的限制。
- 增加的 API Server 负载会影响作业提交延迟和整个集群的监控性能。
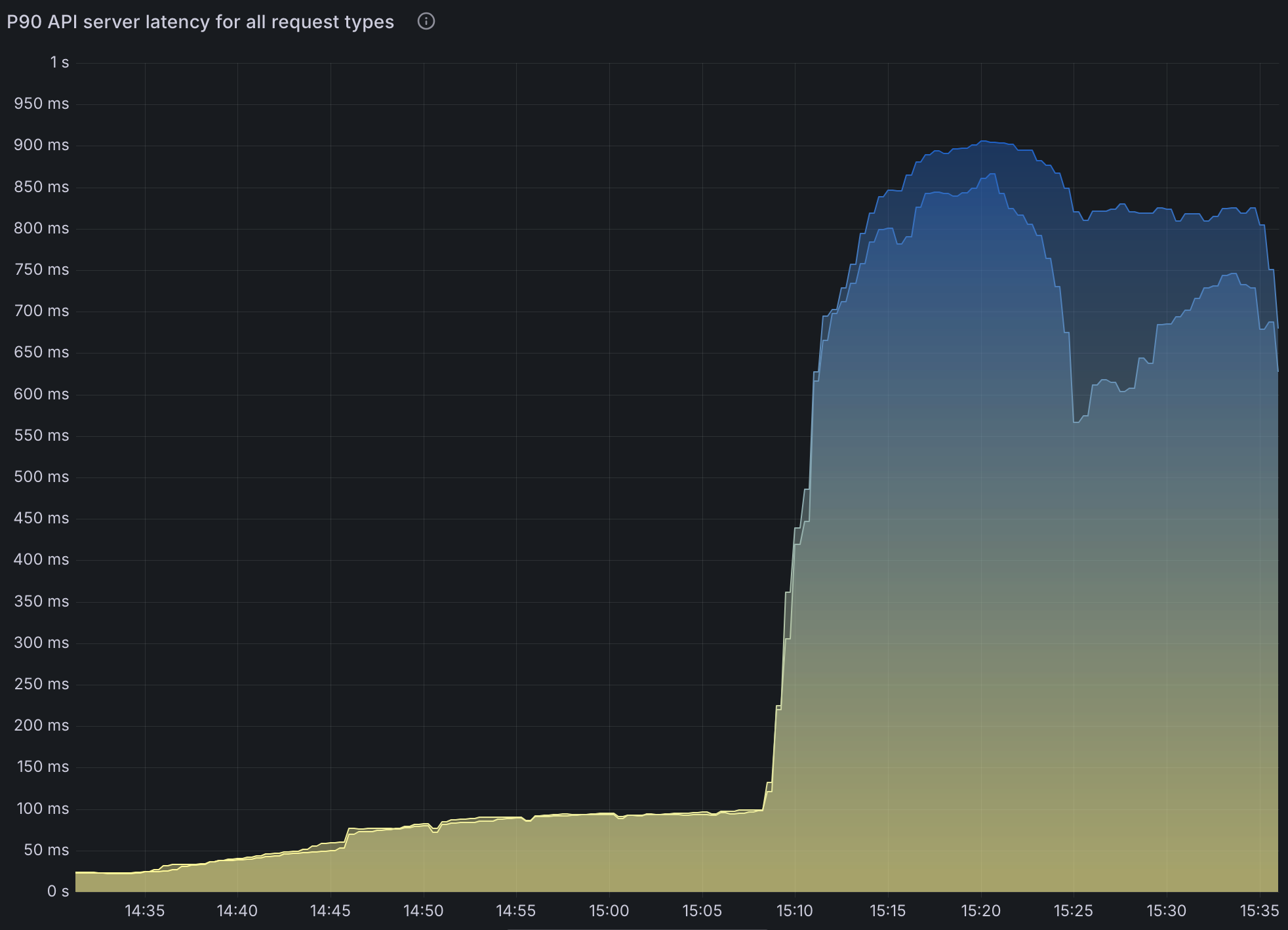
请注意,在 SparkApplication 配置中设置 spark.kubernetes.executor.enablePollingWithResourceVersion: "true" 可以大大缓解此问题。
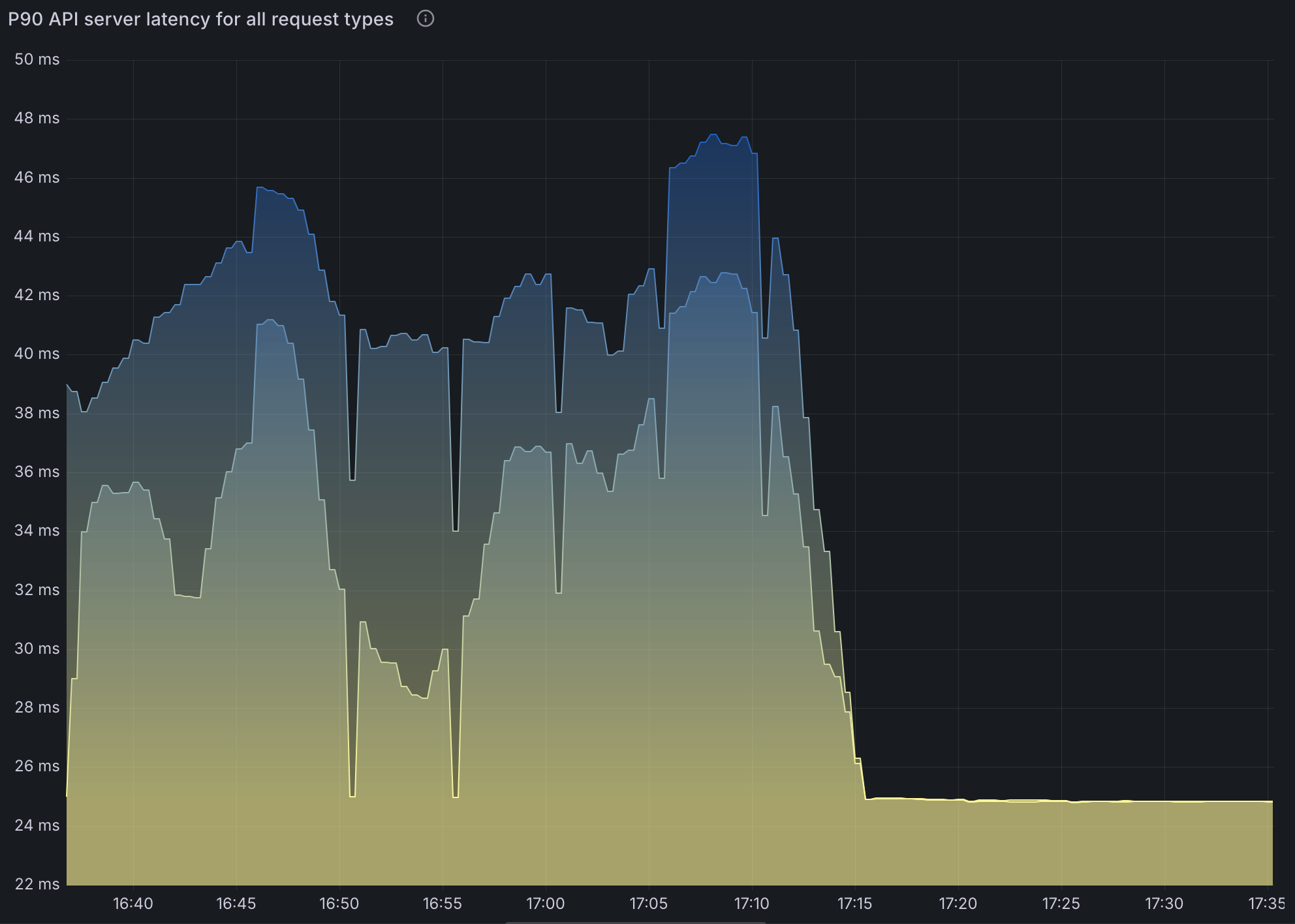
然而,这意味着 API Server 可能会返回任何版本的 Pods,尤其是在高可用性 (HA) 配置中。这可能导致 Spark 无法恢复的不一致状态。
6000 个 Spark 作业。分布在三个命名空间中,每个命名空间有 2000 个应用。- 控制器 worker 设置为
10。 - 每分钟处理
130 apps。 - 使用 了
~25 cores。 - API 延迟显著增加。
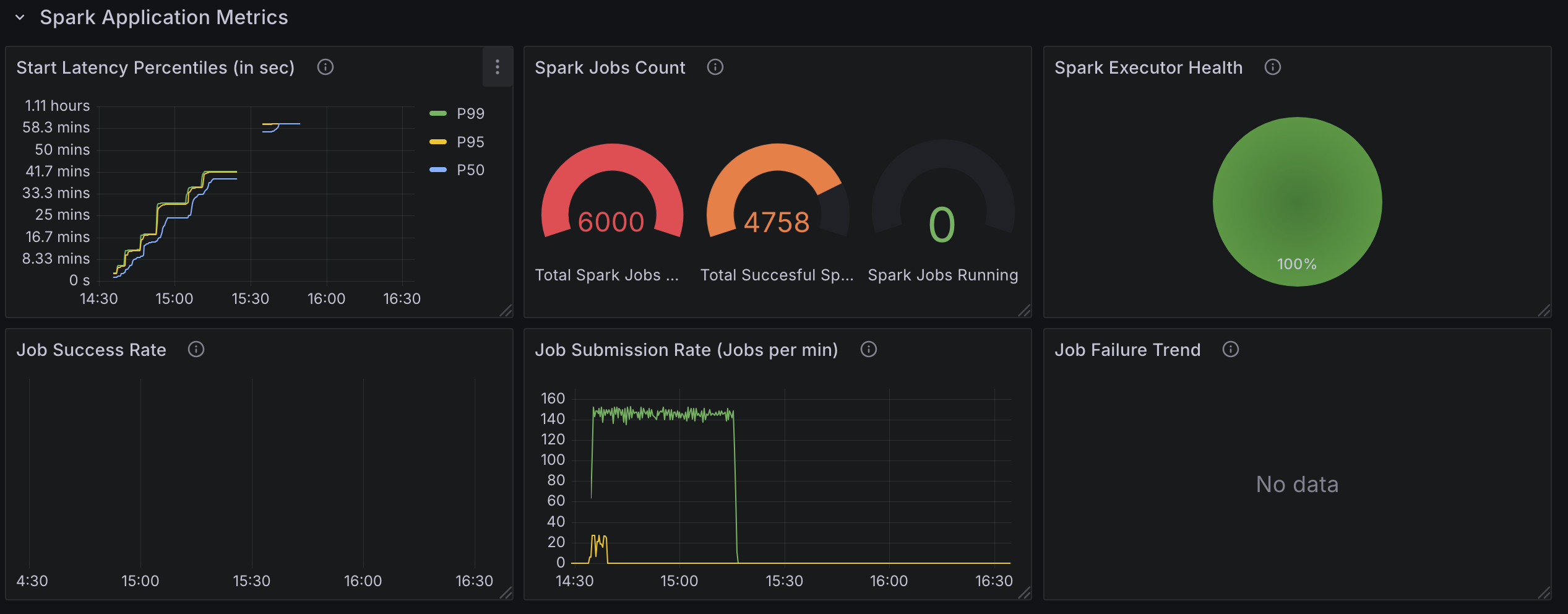
测试 2:6000 个 Spark Applications,配备 20 个控制器 Worker
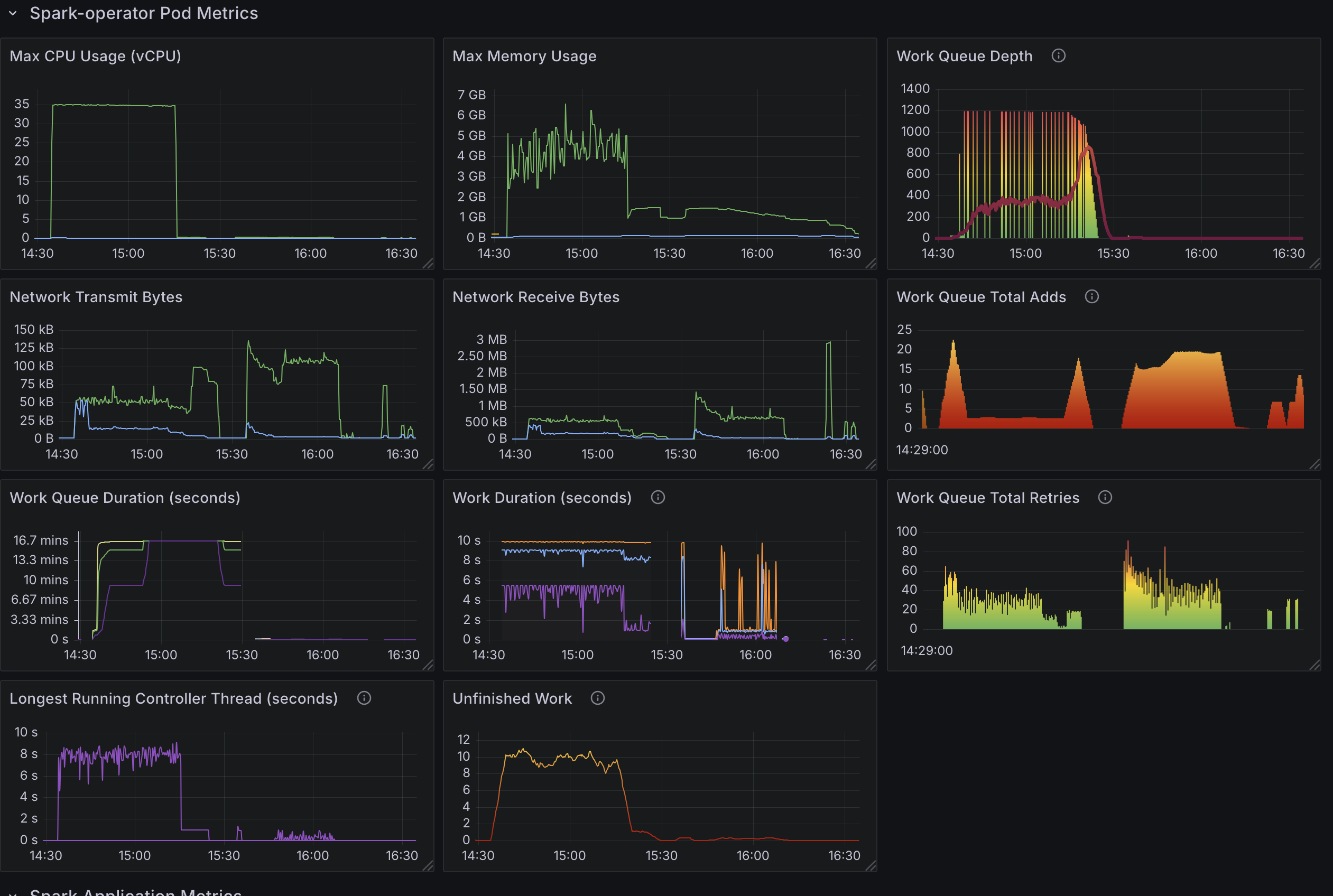
- 6000 个 Spark 作业。分布在三个命名空间中,每个命名空间有 2000 个应用。
变更
- 将可用配置的 goroutine 数量从
10(默认)增加到20。
观察
- 每分钟处理
140-150个应用。 - 使用 了
35个核心。 - 其他结果与默认配置结果相似。
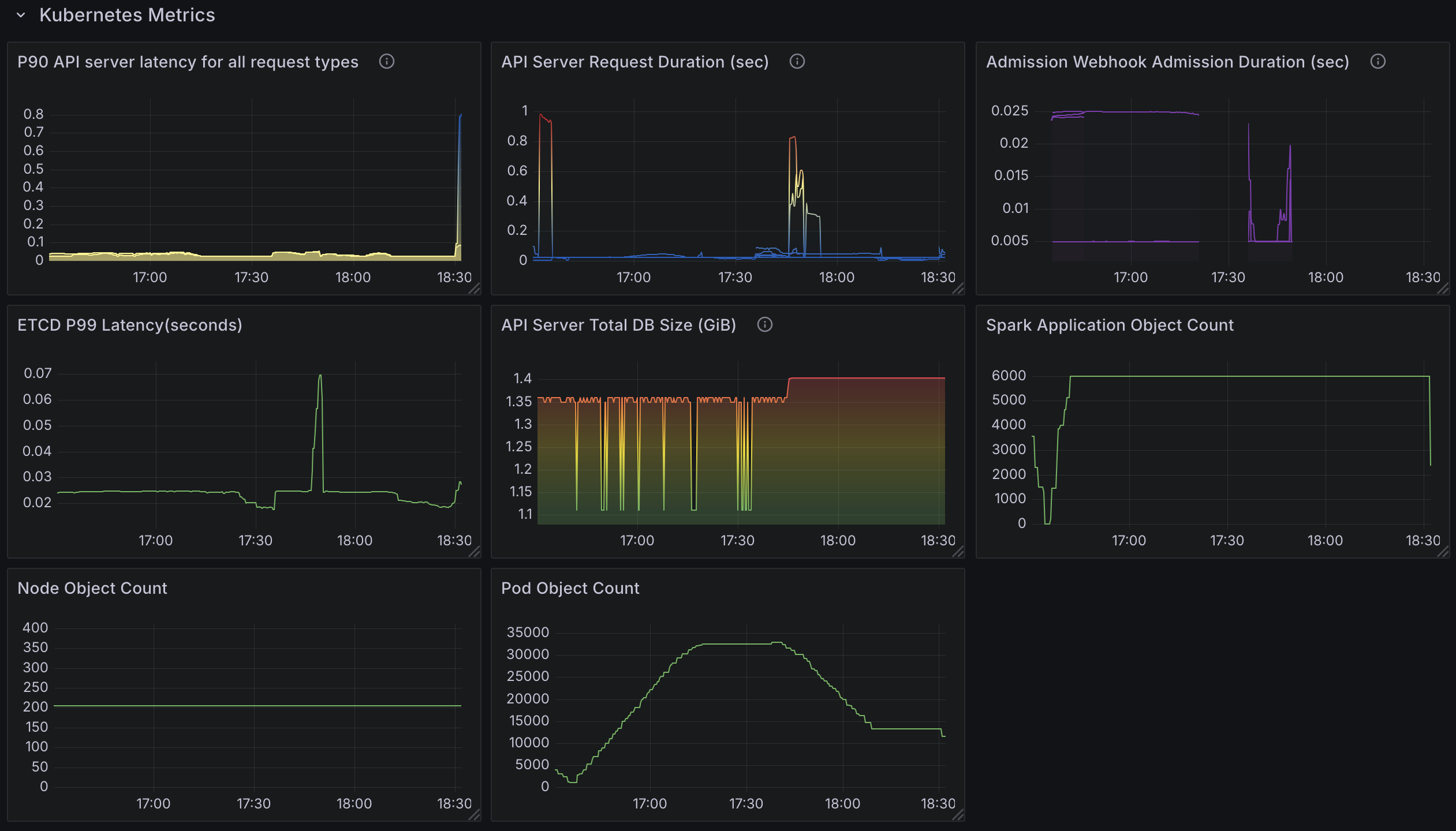
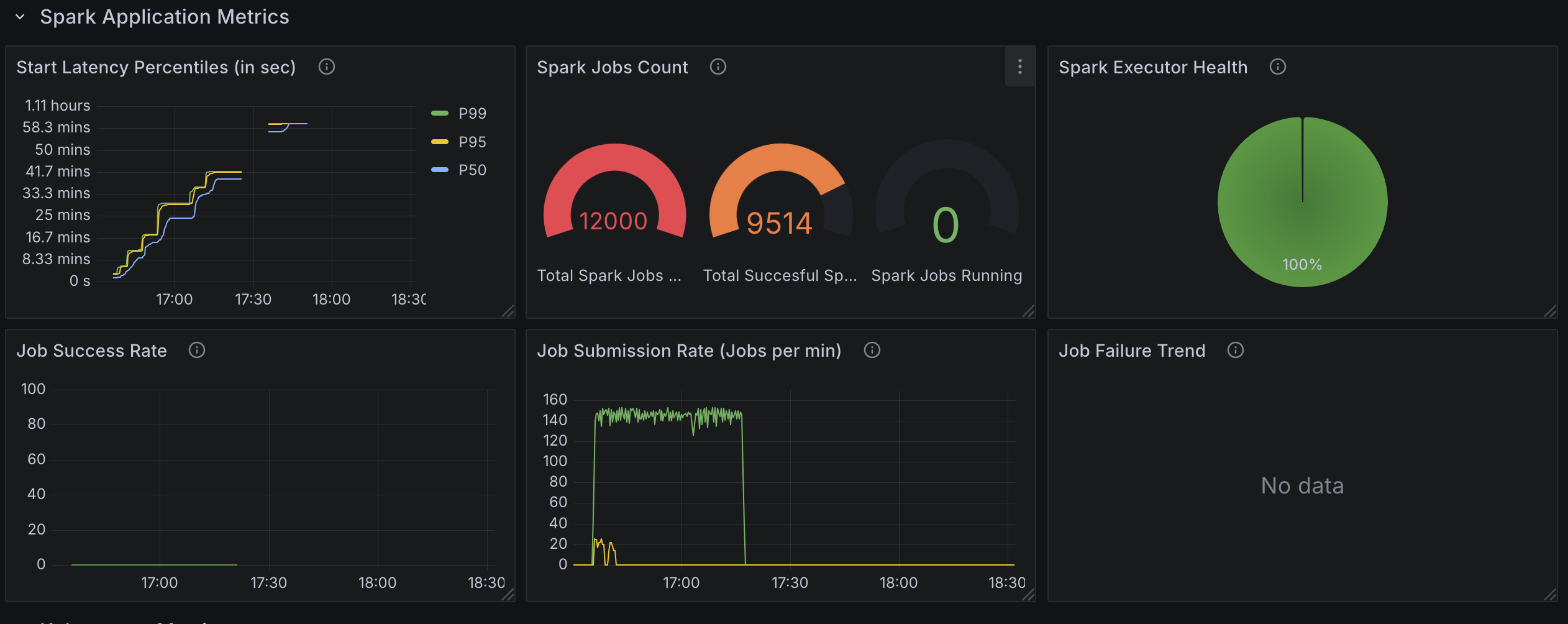
测试 3:6000 个 Spark Applications,配备 20 个控制器 Worker 且资源版本设置为 0。
变更
- 将可用配置的 goroutine 数量从
10(默认)增加到20。 - 在 SparkApplication 配置中设置
spark.kubernetes.executor.enablePollingWithResourceVersion: "true"。 6000个 Spark 作业。分布在三个命名空间中,每个命名空间有2000个应用。
观察
- API 延迟的增加几乎消失,符合预期。
- 每分钟处理
140-150个应用。 - 使用 了
35 cores。

测试 4:6000 个 Spark Applications(禁用 Webhook)
测试配置
- 与测试 1 相同,但禁用了 webhook 以评估其对性能的影响。
观察
- 禁用 webhook 使每个作业的启动延迟减少了约 60 秒,提高了整体吞吐量。
主要结论
Spark Operator 中的 CPU 约束
- Spark Operator 的控制器 Pod 严重受 CPU 限制。将控制器 worker (goroutine) 的数量从
10增加到20使处理速率从每分钟~130个应用提高到~150个,但 CPU 使用率达到峰值,表明 CPU 资源是限制因素。 - 内存使用量保持稳定,表明内存不是 Operator 的瓶颈。
Kubernetes API Server 延迟
- 高 API Server 延迟,在重负载下(例如,创建
36000个 Pod)峰值达到约 600 毫秒,显著影响了作业提交和状态更新。此延迟主要由 Spark 频繁查询执行程序 Pod 引起,而非 Operator 本身。 - 启用
spark.kubernetes.executor.enablePollingWithResourceVersion: "true"降低了 API 延迟,但在高可用性 (HA) 设置中引入了 Pod 状态不一致的风险,可能导致作业失败。
Webhook 开销
- 启用 webhook 为每个作业增加了
~60秒的延迟,显著降低了吞吐量。禁用 webhook 通过利用 Pod Templates 提高了性能,但牺牲了验证和变异功能。
命名空间管理问题
- 在单个命名空间中运行 6000 个 SparkApplications 导致 Pod 失败,错误为:
exec /opt/entrypoint.sh: argument list too long。 - 发生此问题是因为每个 SparkApplication 创建一个 Service 对象,而 Service 的累积使存储主机和端口详情的环境变量溢出。Service 对象在作业完成后仍然存在,除非手动删除 SparkApplication 对象。有关更多信息,请参阅此文章。
处理延迟
- Operator 每分钟处理
~130–150个应用,对于大型工作负载(例如,在6000个作业提交中,驱动程序 Pod 启动需要~1小时)导致显著延迟。由于 Operator 优先处理新提交而不是更新,一些作业的状态更新滞后长达30 分钟。
建议
为了优化 Kubeflow Spark Operator 以应对高并发工作负载,请考虑以下策略:
部署多个 Spark Operator 实例
- 原因: 单个 Operator 实例由于 CPU 和处理限制难以应对大型工作负载。将负载分布到多个实例可以利用并行性来减少处理时间。
- 方法:
- 使用 Helm 为每个命名空间部署一个单独的 Spark Operator 实例(例如,
spark-team-a、spark-team-b、spark-team-c)。 - 配置每个实例,将其
spark.jobNamespaces设置为其对应的命名空间。
- 使用 Helm 为每个命名空间部署一个单独的 Spark Operator 实例(例如,
- 益处: 使用三个实例,每个实例处理
6000个作业提交中的2000 jobs,处理时间可在~15分钟内完成(假设均匀分布),而单个实例则需要~1小时。 - 注意事项:
- 为每个实例分配一个具有命名空间范围 RBAC 规则的唯一服务账户,以实现隔离。
- Helm chart 默认具有集群范围的权限,因此可能需要自定义配置。
禁用 Webhook
- 原因: Webhook 为每个作业增加
~60秒的延迟,严重影响高并发下的吞吐量。 - 方法: 在 Helm chart 中将
webhook.enable设置为 false。 - 益处: 消除此开销可加快作业启动速度,如基准测试所示。
- 注意事项:
- 使用
Pod Templates进行卷配置、节点选择器和污点,以替代 webhook 功能。
- 使用
增加 Worker 数量
- 原因: 更多的控制器 worker (goroutine) 允许 Operator 并发处理作业,如果 CPU 资源可用,可以提高吞吐量。
- 方法: 通过 Helm chart 将 controller.workers 从
10增加到20或30。选择计算密集型节点来运行 Spark Operator(例如,本测试中使用的c5.9xlarge)。 - 益处: 测试显示,使用
20个 worker 时,处理速率从每分钟~130个应用增加到~150个。在可用36 vCPUs的情况下,每个 worker 在20个 worker 时可以使用~1.8 vCPUs,可能可以进一步扩展。 - 注意事项:
- 监控 CPU 使用率(例如,通过启用
prometheus.metrics.enable的 Prometheus)以避免饱和。 - 如果主要瓶颈是 API 延迟而非 CPU,则效果可能有限。
- 监控 CPU 使用率(例如,通过启用
启用批处理调度器
- 原因: 这些基准测试未涵盖批处理调度器的使用,但
Volcano或Yunikorn等自定义批处理调度器可以优化资源分配,减少大规模作业的 Pod 创建时间。 - 方法:
- 在 Helm chart 中将
batchScheduler.enable设置为 true。 - 指定一个调度器(例如,
Volcano或Yunikorn)并在集群中安装。
- 在 Helm chart 中将
- 益处: 增强的调度效率可提高高并发下的性能。
优化 Kubernetes 集群性能
- 原因: 负载下的高 API Server 延迟(例如,跨
200 nodes创建36000个 Pod)阻碍了作业处理。现有节点容量(m6a.4xlarge,16 vCPUs,64GBRAM,每个节点最多220个 Pod)是足够的,但需要关注 API Server 自动扩缩容和调度器效率。 - 方法:
- 扩缩 API Server 副本或分配更多资源(许多云提供商(包括 Amazon EKS)会自动处理 API Server 扩缩容)。
管理命名空间使用
- 原因: 在一个命名空间中存在过多的 SparkApplications(例如,
6000)会导致 Pod 失败,原因是持久性 Service 对象引起的环境变量溢出。 - 方法:
- 将 Spark 作业分布到多个命名空间(例如,
spark-team-a、spark-team-b、spark-team-c)。 - 为 SparkApplication 对象设置
timeToLiveSeconds持续时间,或部署自定义垃圾回收 (GC) 服务以移除已完成的应用及其 Service。
- 将 Spark 作业分布到多个命名空间(例如,
- 益处: 防止故障并在高作业量下确保可靠运行。
- 注意事项: Service 对象在作业完成后不会自动删除,因此主动清理至关重要。
监控和调优
- 原因: 持续监控可识别瓶颈并验证优化效果。
- 方法: 使用提供的 Grafana 面板(通过 Helm 启用)跟踪工作队列深度、CPU 使用率、API 延迟和处理速率等指标。
- 益处: 数据驱动的调优确保 Operator 能够有效地为大型工作负载进行扩缩。
- 注意事项: 关注 CPU 饱和度和 API 响应能力,以指导调整。
未来工作
我们将继续运行基准测试,以评估这些增强措施的有效性。我们的目标是通过探索以下社区建议的策略来提高 Spark Operator 的性能:
基于 Go 的 Spark Submit: 从当前基于 Java 的
spark-submit迁移到基于 Go 的实现,以减少 JVM 启动延迟并提高作业提交效率。控制器分片: 增强 Spark Operator 的控制器以实现并行处理并提高可伸缩性。
致谢
我们衷心感谢 AWS 为这些基准测试提供了必要的基础设施。我们也感谢 Spark Operator 社区贡献者 Manabu McCloskey、Vara Bonthu、Alan Halcyon 和 Ratnopam Chakrabarti 在执行这些基准测试中的努力。