使用 Kubeflow Pipelines SDK
如何使用 Kubeflow Pipelines SDK
旧版本
此页面介绍的是 Kubeflow Pipelines V1,最新信息请参阅 V2 文档。
注意,虽然 V2 后端能够运行由 V1 SDK 提交的流水线,我们强烈建议迁移到 V2 SDK。供参考,V1 SDK 的最终发布版本是 kfp==1.8.22,其参考文档可在此处获取。
本指南提供了示例,演示了如何使用 Kubeflow Pipelines SDK。
开始之前
要按照本指南中的示例进行操作,您必须安装 Kubeflow Pipelines SDK 版本 0.2.5 或更高版本。请使用以下说明安装 Kubeflow Pipelines SDK 并检查 SDK 版本。
- 安装 Kubeflow Pipelines SDK
- 运行以下命令检查 SDK 版本响应应类似如下所示
pip list | grep kfpkfp 0.2.5 kfp-server-api 0.2.5
示例
请使用以下示例了解更多关于 Kubeflow Pipelines SDK 的信息。
示例 1:使用 SDK 创建流水线和流水线版本
以下示例演示了如何使用 Kubeflow Pipelines SDK 创建流水线和流水线版本。
在此示例中,您将
- 使用
kfp.Client从本地文件创建流水线。创建流水线时,会自动创建一个默认的流水线版本。 - 使用
kfp.Client为上一步中创建的流水线添加流水线版本。
import kfp
import os
host = <host>
pipeline_file_path = <path to pipeline file>
pipeline_name = <pipeline name>
pipeline_version_file_path = <path to pipeline version file>
pipeline_version_name = <pipeline version name>
client = kfp.Client(host)
pipeline_file = os.path.join(pipeline_file_path)
pipeline = client.pipeline_uploads.upload_pipeline(pipeline_file, name=pipeline_name)
pipeline_version_file = os.path.join(pipeline_version_file_path)
pipeline_version = client.pipeline_uploads.upload_pipeline_version(pipeline_version_file,
name=pipeline_version_name,
pipelineid=pipeline.id)
- host:您的 Kubeflow Pipelines 集群主机名。
- 流水线文件路径:存储您的流水线 YAML 文件的目录路径。
- 流水线名称:您的流水线文件名。
- 流水线版本文件路径:存储您的新版本流水线 YAML 文件的目录路径。
- 流水线版本名称:您的流水线版本文件名。
注意:流水线名称在您的 Kubeflow Pipelines 集群中必须是唯一的。流水线版本名称在每条流水线中必须是唯一的。
使用 SDK 向现有流水线添加版本
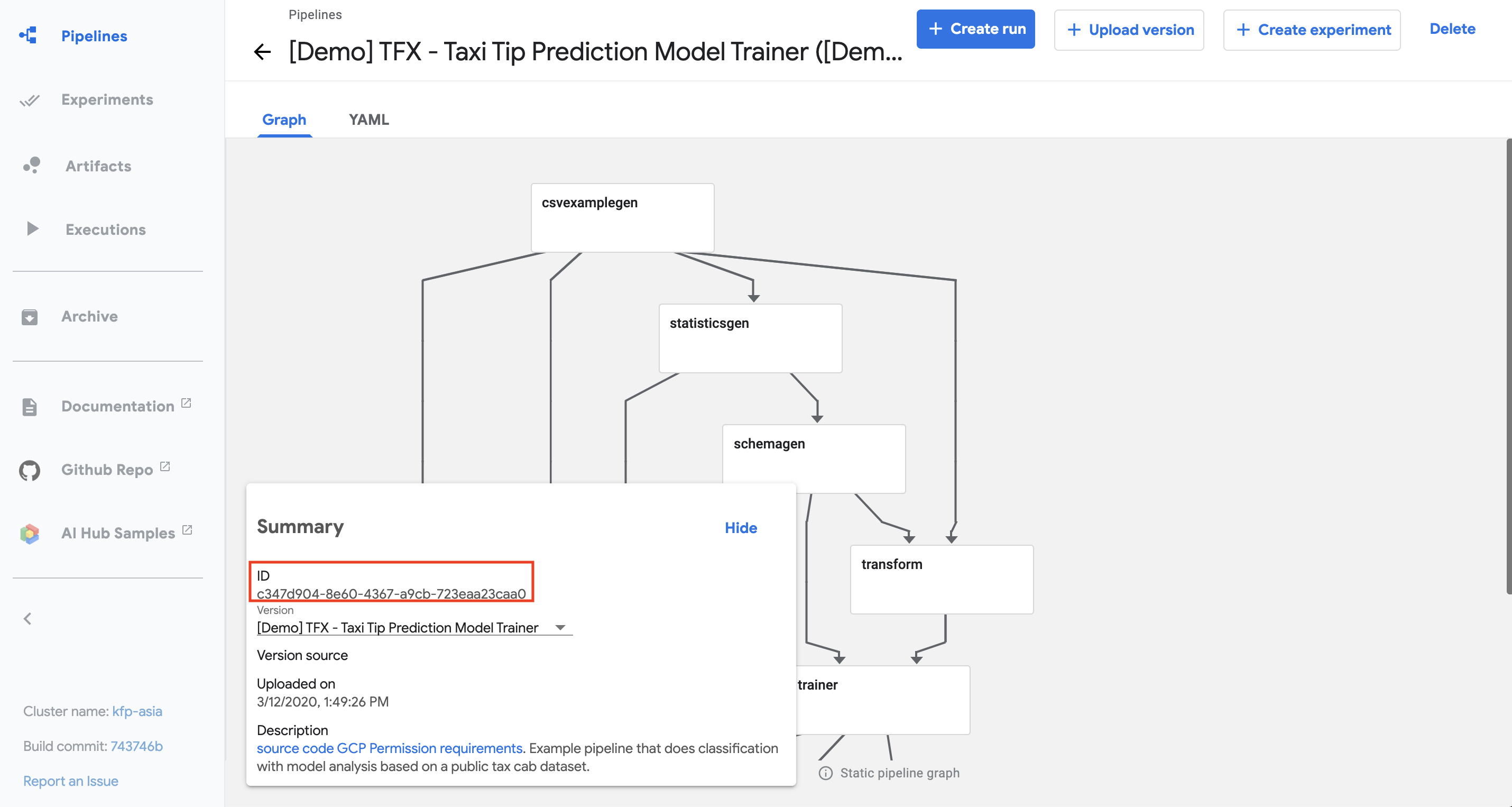
要为现有流水线添加版本,您必须找到该流水线的 ID,并将其与 upload_pipeline_version 方法一起使用。查找流水线 ID 的方法如下:
- 打开 Kubeflow Pipelines UI。您的流水线列表将出现。
- 点击您的流水线名称。流水线详情页面将出现。
- 流水线 ID 列在摘要卡中,如下所示。
示例 2:使用过滤器列出流水线
以下示例演示了如何使用 Kubeflow Pipelines SDK 列出具有特定流水线名称的流水线。如果调用 list_pipelines 方法时没有输入参数,它将列出所有流水线。但是,您可以指定一个过滤器作为输入参数来列出具有特定名称的流水线。考虑到 Kubeflow Pipelines 要求流水线名称唯一,列出具有特定名称的流水线最多返回一条流水线。
import kfp
import json
# 'host' is your Kubeflow Pipelines API server's host address.
host = <host>
# 'pipeline_name' is the name of the pipeline you want to list.
pipeline_name = <pipeline name>
client = kfp.Client(host)
# To filter on pipeline name, you can use a predicate indicating that the pipeline
# name is equal to the given name.
# A predicate includes 'key', 'op' and 'string_value' fields.
# The 'key' specifies the property you want to apply the filter to. For example,
# if you want to filter on the pipeline name, then 'key' is set to 'name' as
# shown below.
# The 'op' specifies the operator used in a predicate. The operator can be
# EQUALS, NOT_EQUALS, GREATER_THAN, etc. The complete list is at [filter.proto](https://github.com/kubeflow/pipelines/blob/sdk/release-1.8/backend/api/filter.proto#L32)
# When using the operator in a string-typed predicate, you need to use the
# corresponding integer value of the enum. For Example, you can use the integer
# value 1 to indicate EQUALS as shown below.
# The 'string_value' specifies the value you want to filter with.
filter = json.dumps({'predicates': [{'key': 'name', 'op': 1, 'string_value': '{}'.format(pipeline_name)}]})
pipelines = client.pipelines.list_pipelines(filter=filter)
# The pipeline with the given pipeline_name, if exists, is in pipelines.pipelines[0].
示例 3:使用流水线版本创建运行
查看 run_service_api.ipynb notebook,了解更多关于使用流水线版本创建运行的信息。
最后修改时间:2025 年 3 月 29 日:website: Add dark theme (#3981) (4f092f1)