基于 Python 的可视化(已弃用)
旧版本
本页面介绍的是 Kubeflow Pipelines V1,请查阅 V2 文档获取最新信息。
注意,虽然 V2 后端能够运行由 V1 SDK 提交的 pipeline,但我们强烈建议迁移到 V2 SDK。作为参考,V1 SDK 的最终版本是 kfp==1.8.22,其参考文档在此处提供。
已弃用
基于 Python 的可视化已弃用。我们建议改为通过 Kubeflow Pipelines SDK 获取数据,并在您自己的 notebook 中进行可视化。本页面介绍基于 Python 的可视化,如何创建以及如何在 Kubeflow Pipelines UI 中使用它们来可视化结果。基于 Python 的可视化在 Kubeflow Pipelines 0.1.29 及更高版本,以及 Kubeflow 0.7.0 及更高版本中可用。
虽然基于 Python 的可视化旨在成为在 Kubeflow Pipelines UI 中可视化数据的主要方法,但它们并不能取代之前在 Kubeflow Pipelines UI 中可视化数据的方法。在考虑在 pipeline 中使用哪种可视化方法时,请查阅以下部分中基于 Python 可视化的限制,并将其与您可视化的要求进行比较。
简介
基于 Python 的可视化是在 Kubeflow Pipelines UI 中可视化结果的一种新方法。这种新的可视化方法是通过使用 nbconvert 来完成的。除了使用 nbconvert,现在即使 pipeline 本身不包含组件,也可以可视化 pipeline 的结果,因为可视化结果的过程现已与 pipeline 解耦。
基于 Python 的可视化提供了两类可视化。第一类是预定义可视化。这些可视化在 Kubeflow Pipelines 中默认提供,为您和您的客户提供了一种轻松快速生成强大可视化效果的方式。第二类是自定义可视化。自定义可视化允许您和您的客户提供 Python 可视化代码来生成可视化。这些可视化允许在可视化结果时进行快速开发、实验和定制。
使用预定义可视化
预定义矩阵可视化

- 打开运行详情。
- 选择一个组件。
- 选择哪个组件无关紧要。但是,如果您想可视化特定组件的输出,在该组件内执行操作会更方便。
- 选择Artifacts选项卡。
- 在选项卡顶部,您应该会看到一个名为“可视化创建器”的卡片。
- 在卡片内,提供可视化类型、源以及任何必要的参数。
- 任何必需或可选的参数都将显示为占位符。
- 点击生成可视化。
- 向下滚动查看生成的可视化。
预定义 TFX 可视化
- 在 Pipelines 页面上,点击[示例] 统一 DSL - 出租车小费预测模型训练器以打开 Pipeline 详情页面。
- 在 Pipeline 详情页面上,点击创建运行。
- 在创建运行页面上,
- 使用您选择的运行名称和实验名称。
- 在 pipeline-root 字段中,指定您有写入权限的存储桶。例如,输入 Google Cloud Storage 存储桶或 Amazon S3 存储桶的路径。
- 点击开始创建运行。
- 运行完成后,在运行详情页面上,点击任意步骤。例如,点击如上视频所示的第一个步骤 csvexamplegen。
- 在所选步骤的侧面板中,
- 点击Artifacts选项卡。
- 在可视化创建器部分,从下拉菜单中选择 TFDV。
- 在源字段中,使用 gs://ml-pipeline-playground/tfx_taxi_simple/data/data.csv,这是本次运行使用的输入数据。
- 点击生成可视化并等待。
- 移动到 Artifacts 选项卡底部查找生成的可视化。
使用自定义可视化
- 在 Kubeflow Pipelines 中启用自定义可视化。
- 打开运行详情。
- 选择一个组件。
- 选择哪个组件无关紧要。但是,如果您想可视化特定组件的输出,在该组件内执行操作会更方便。
- 选择Artifacts选项卡。
- 在选项卡顶部,您应该会看到一个名为“可视化创建器”的卡片。
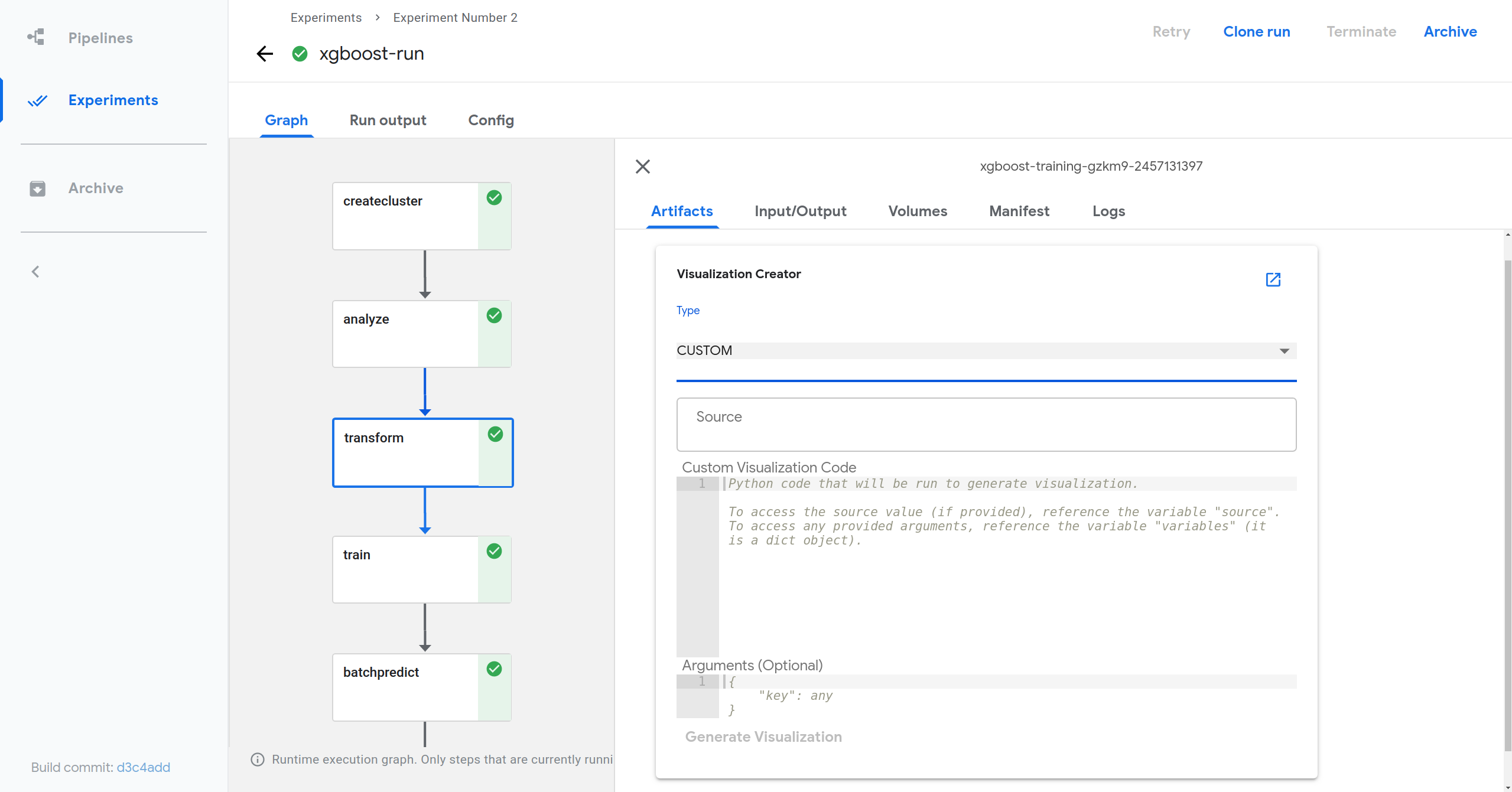
- 在卡片中,选择自定义可视化类型,然后提供源和任何必要的参数(对于自定义可视化,源和参数变量是可选的)。
- 提供自定义可视化代码。
- 点击生成可视化。
- 向下滚动查看生成的可视化。
上述步骤的演示如下。
- 在 Pipelines 页面上,点击[示例] 统一 DSL - 出租车小费预测模型训练器以打开 Pipeline 详情页面。
- 在 Pipeline 详情页面上,点击创建运行。
- 在创建运行页面上,
- 使用您选择的运行名称和实验名称,或者直接使用为您选择的默认名称。
- 在 pipeline-root 字段中,指定您有写入权限的存储桶。例如,输入 Google Cloud Storage 存储桶或 Amazon S3 存储桶的路径。
- 点击开始创建运行。
- 运行完成后,在运行详情页面上,点击 statisticsgen 步骤。此步骤的输出是由 Tensorflow Data Validation 生成的统计数据。
- 在所选步骤的侧面板中,
- 点击输入/输出选项卡以查找 mlpipeline-ui-metadata 项并点击其中的 minio 链接。这将在新浏览器选项卡中打开包含输出文件路径的信息。复制演示视频中显示的输出文件路径。
- 回到运行详情页面,点击Artifacts选项卡。
- 在选项卡顶部,您应该会看到一个名为“可视化创建器”的卡片,从下拉菜单中选择自定义。
- 在自定义可视化代码字段中,填写以下代码片段,并将 [output file path] 替换为您刚刚从 mlpipeline-ui-metadata 复制的输出文件路径。
import tensorflow_data_validation as tfdv stats = tfdv.load_statistics('[output file path]/stats_tfrecord') tfdv.visualize_statistics(stats) - 点击生成可视化并等待。
- 移动到 Artifacts 选项卡底部查找生成的可视化。
已知限制
无法并发生成多个可视化。
- 这是因为使用了单个 Python 内核来生成可视化。
- 如果可视化是您工作流的主要部分,建议增加可视化部署 YAML 文件中或可视化服务部署本身的副本数量。
- 请注意,这并不能直接解决问题,而是降低了生成可视化时遇到延迟的可能性。
生成时间超过 30 秒的可视化将会失败。
生成的可视化的 HTML 内容不能超过 4MB。
gRPC 默认将服务器可以发送和接收的最大大小限制为 4MB。要允许生成大于 4MB 的可视化,您必须手动为 gRPC 设置 MaxCallRecvMsgSize。这可以通过修改 main.go 中提供给 gRPC 服务器的选项来完成,如下所示:
var maxCallRecvMsgSize = 4 * 1024 * 1024 if serviceName == "Visualization" { // Only change the maxCallRecvMesSize if it is for visualizations maxCallRecvMsgSize = 50 * 1024 * 1024 } opts := []grpc.DialOption{ grpc.WithDefaultCallOptions(grpc.MaxCallRecvMsgSize(maxCallRecvMsgSize)), grpc.WithInsecure(), }