介绍
旧版本
本页面是关于 Kubeflow Pipelines V1 的,请参阅V2 文档以获取最新信息。
注意,虽然 V2 后端能够运行由 V1 SDK 提交的 pipeline,我们强烈建议迁移到 V2 SDK。供参考,V1 SDK 的最终版本是kfp==1.8.22,其参考文档可在此处获取。
Kubeflow Pipelines 是一个基于 Docker 容器构建和部署可移植、可扩展机器学习 (ML) 工作流的平台。
快速入门
遵循pipeline 快速入门指南运行您的第一个 pipeline。
什么是 Kubeflow Pipelines?
Kubeflow Pipelines 平台由以下部分组成:
- 用于管理和跟踪实验、作业和运行的用户界面 (UI)。
- 用于调度多步骤 ML 工作流的引擎。
- 用于定义和操作 pipeline 和组件的 SDK。
- 用于使用 SDK 与系统交互的 Notebooks。
以下是 Kubeflow Pipelines 的目标:
- 端到端编排:启用并简化机器学习 pipeline 的编排。
- 轻松实验:让您轻松尝试各种想法和技术,并管理您的各种试验/实验。
- 轻松重用:使您能够重用组件和 pipeline,从而快速创建端到端解决方案,而无需每次都重新构建。
Kubeflow Pipelines 可作为 Kubeflow 的核心组件或独立安装使用。
由于 kubeflow/pipelines#1700,Kubeflow Pipelines 中的容器构建器目前仅为 Google Cloud Platform (GCP) 准备凭据。因此,容器构建器仅支持 Google Container Registry。但是,您可以在其他注册表中存储容器镜像,前提是您正确设置了凭据以获取镜像。
什么是 pipeline?
一个 pipeline 是一个 ML 工作流的描述,包括工作流中的所有组件以及它们如何以图的形式组合在一起。(请参阅下面的屏幕截图,其中显示了 pipeline 图的示例。)pipeline 包括运行 pipeline 所需的输入(参数)的定义以及每个组件的输入和输出的定义。
开发完 pipeline 后,您可以在 Kubeflow Pipelines UI 上上传和共享它。
一个 pipeline 组件 是一组自包含的用户代码,打包为Docker 镜像,用于执行 pipeline 中的一个步骤。例如,一个组件可以负责数据预处理、数据转换、模型训练等。
Pipeline 示例
下面的屏幕截图和代码展示了 xgboost-training-cm.py pipeline,它使用 CSV 格式的结构化数据创建一个 XGBoost 模型。您可以在GitHub上查看该 pipeline 的源代码和其他信息。
Pipeline 的运行时执行图
下面的屏幕截图显示了示例 pipeline 在 Kubeflow Pipelines UI 中的运行时执行图

代表 pipeline 的 Python 代码
以下是定义 xgboost-training-cm.py pipeline 的 Python 代码片段。您可以在GitHub上查看完整代码。
@dsl.pipeline(
name='XGBoost Trainer',
description='A trainer that does end-to-end distributed training for XGBoost models.'
)
def xgb_train_pipeline(
output='gs://your-gcs-bucket',
project='your-gcp-project',
cluster_name='xgb-%s' % dsl.RUN_ID_PLACEHOLDER,
region='us-central1',
train_data='gs://ml-pipeline-playground/sfpd/train.csv',
eval_data='gs://ml-pipeline-playground/sfpd/eval.csv',
schema='gs://ml-pipeline-playground/sfpd/schema.json',
target='resolution',
rounds=200,
workers=2,
true_label='ACTION',
):
output_template = str(output) + '/' + dsl.RUN_ID_PLACEHOLDER + '/data'
# Current GCP pyspark/spark op do not provide outputs as return values, instead,
# we need to use strings to pass the uri around.
analyze_output = output_template
transform_output_train = os.path.join(output_template, 'train', 'part-*')
transform_output_eval = os.path.join(output_template, 'eval', 'part-*')
train_output = os.path.join(output_template, 'train_output')
predict_output = os.path.join(output_template, 'predict_output')
with dsl.ExitHandler(exit_op=dataproc_delete_cluster_op(
project_id=project,
region=region,
name=cluster_name
)):
_create_cluster_op = dataproc_create_cluster_op(
project_id=project,
region=region,
name=cluster_name,
initialization_actions=[
os.path.join(_PYSRC_PREFIX,
'initialization_actions.sh'),
],
image_version='1.2'
)
_analyze_op = dataproc_analyze_op(
project=project,
region=region,
cluster_name=cluster_name,
schema=schema,
train_data=train_data,
output=output_template
).after(_create_cluster_op).set_display_name('Analyzer')
_transform_op = dataproc_transform_op(
project=project,
region=region,
cluster_name=cluster_name,
train_data=train_data,
eval_data=eval_data,
target=target,
analysis=analyze_output,
output=output_template
).after(_analyze_op).set_display_name('Transformer')
_train_op = dataproc_train_op(
project=project,
region=region,
cluster_name=cluster_name,
train_data=transform_output_train,
eval_data=transform_output_eval,
target=target,
analysis=analyze_output,
workers=workers,
rounds=rounds,
output=train_output
).after(_transform_op).set_display_name('Trainer')
_predict_op = dataproc_predict_op(
project=project,
region=region,
cluster_name=cluster_name,
data=transform_output_eval,
model=train_output,
target=target,
analysis=analyze_output,
output=predict_output
).after(_train_op).set_display_name('Predictor')
_cm_op = confusion_matrix_op(
predictions=os.path.join(predict_output, 'part-*.csv'),
output_dir=output_template
).after(_predict_op)
_roc_op = roc_op(
predictions_dir=os.path.join(predict_output, 'part-*.csv'),
true_class=true_label,
true_score_column=true_label,
output_dir=output_template
).after(_predict_op)
dsl.get_pipeline_conf().add_op_transformer(
gcp.use_gcp_secret('user-gcp-sa'))
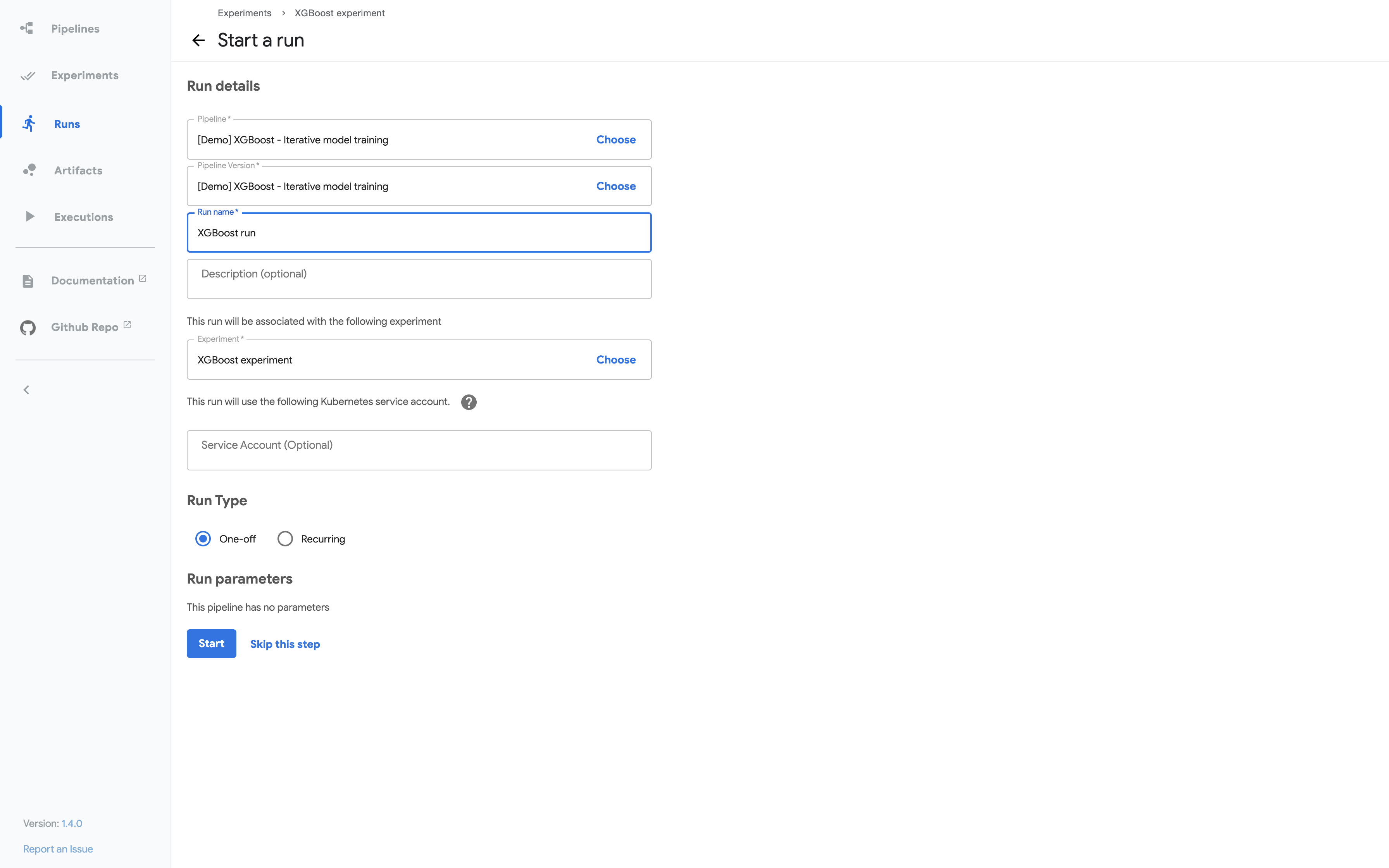
Kubeflow Pipelines UI 上的 pipeline 输入数据
下面的部分屏幕截图显示了 Kubeflow Pipelines UI 用于启动 pipeline 运行的界面。代码中的 pipeline 定义决定了 UI 表单中显示哪些参数。pipeline 定义还可以为参数设置默认值
Pipeline 输出
以下屏幕截图显示了在 Kubeflow Pipelines UI 上可见的 pipeline 输出示例。
预测结果
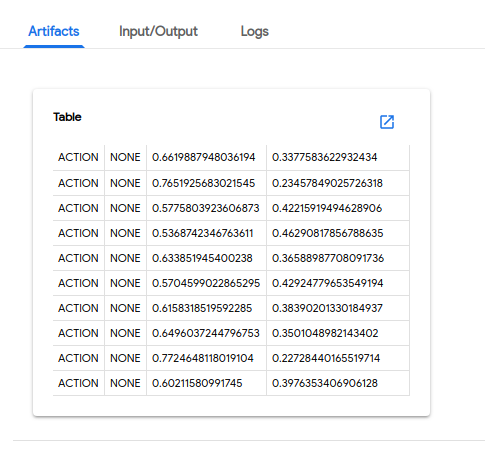
混淆矩阵

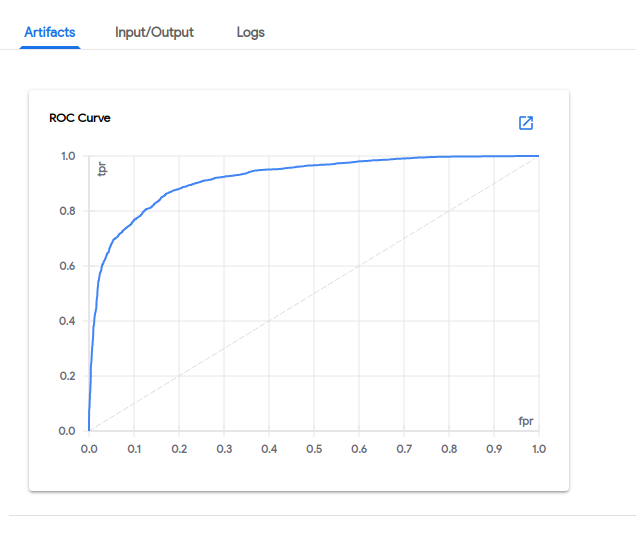
受试者工作特征曲线 (ROC 曲线)
架构概览

从高层次上看,pipeline 的执行过程如下:
Python SDK:您可以使用 Kubeflow Pipelines 领域特定语言 (DSL) 创建组件或指定 pipeline。
DSL 编译器:DSL 编译器将您的 pipeline 的 Python 代码转换为静态配置 (YAML)。
Pipeline 服务:您调用 Pipeline 服务,从静态配置创建 pipeline 运行。
Kubernetes 资源:Pipeline 服务调用 Kubernetes API 服务器,创建运行 pipeline 所需的 Kubernetes 资源 (CRDs)。
编排控制器:一组编排控制器执行完成 pipeline 所需的容器。这些容器在虚拟机上的 Kubernetes Pod 中执行。一个示例控制器是 Argo Workflow 控制器,它编排任务驱动的工作流。
Artifact 存储:Pod 存储两种数据:
Metadata:实验、作业、pipeline 运行和单个标量指标。指标数据被聚合以便排序和过滤。Kubeflow Pipelines 将 metadata 存储在 MySQL 数据库中。
Artifacts:Pipeline 包、视图和大规模指标(时间序列)。使用大规模指标来调试 pipeline 运行或调查单个运行的性能。Kubeflow Pipelines 将 artifact 存储在 artifact 存储中,例如 Minio 服务器或 Cloud Storage。
MySQL 数据库和 Minio 服务器都由 Kubernetes PersistentVolume 子系统支持。
持久化代理和 ML metadata:Pipeline 持久化代理监视由 Pipeline 服务创建的 Kubernetes 资源,并将这些资源的状态持久化到 ML Metadata 服务中。Pipeline 持久化代理记录执行的容器集及其输入和输出。输入/输出由容器参数或数据 artifact URI 组成。
Pipeline Web 服务器:Pipeline Web 服务器从各种服务收集数据以显示相关视图:当前正在运行的 pipeline 列表、pipeline 执行历史、数据 artifact 列表、关于单个 pipeline 运行的调试信息、关于单个 pipeline 运行的执行状态。
下一步
- 遵循pipeline 快速入门指南,直接从 Kubeflow Pipelines UI 部署 Kubeflow 并运行示例 pipeline。
- 使用Kubeflow Pipelines SDK构建机器学习 pipeline。
- 遵循完整指南,使用Kubeflow Pipelines 示例进行实验。