神经网络架构搜索算法
本页介绍神经网络架构搜索 (NAS) 算法在 Katib 中的工作原理。
高效神经网络架构搜索 (ENAS)
该算法遵循 Hieu Pham、Melody Y. Guan、Barret Zoph、Quoc V. Le 和 Jeff Dean 在 *Efficient Neural Architecture Search via Parameter Sharing* 中提出的思想 (https://arxiv.org/abs/1802.03268),以及 Barret Zoph 和 Quoc V. Le 在 *Neural Architecture Search with Reinforcement Learning* 中提出的思想 (https://arxiv.org/abs/1611.01578)。
该实现基于《通过参数共享实现高效神经网络架构搜索》的 GitHub 仓库和Google 的 ENAS 实现。它使用带有 LSTM 单元的循环神经网络作为控制器来生成神经网络架构候选项。并且该控制器网络通过策略梯度进行更新。然而,它目前不支持参数共享。
Katib 实现
Katib 以特定格式表示神经网络。如果层数 (n) = 12 且可能的运算数 (m) = 6,则架构定义如下
[2]
[0 0]
[1 1 0]
[5 1 0 1]
[1 1 1 0 1]
[5 0 0 1 0 1]
[1 1 1 0 0 1 0]
[2 0 0 0 1 1 0 1]
[0 0 0 1 1 1 1 1 0]
[2 0 1 0 1 1 1 0 0 0]
[3 1 1 1 1 1 1 0 0 1 1]
[0 1 1 1 1 0 0 1 1 1 1 0]
有 n 行,第 ith 行有 i 个元素,描述第 ith 层。请注意,第 0 层是输入,不包含在此定义中。
在每一行中,第一个整数范围从 0 到 m-1,表示该层中的运算。从第二个位置开始,第 kth 个整数是一个布尔值,表示第 (k-2)th 层是否与该层有跳跃连接。(第 (k-1)th 层总是会连接到第 kth 层)
GetSuggestion() 的输出
算法服务的 GetSuggestion() 输出包含两部分:architecture 和 nn_config。
architecture 是神经网络架构定义的 JSON 字符串。格式如上所述。例如:
[[27], [29, 0], [22, 1, 0], [13, 0, 0, 0], [26, 1, 1, 0, 0], [30, 1, 0, 1, 0, 0], [11, 0, 1, 1, 0, 1, 1], [9, 1, 0, 0, 1, 0, 0, 0]]
nn_config 是详细描述层数、输入大小、输出大小以及每个运算索引代表什么的 JSON 字符串。上面架构对应的 nn_config 可以是:
{
"num_layers": 8,
"input_sizes": [32, 32, 3],
"output_sizes": [10],
"embedding": {
"27": {
"opt_id": 27,
"opt_type": "convolution",
"opt_params": {
"filter_size": "7",
"num_filter": "96",
"stride": "2"
}
},
"29": {
"opt_id": 29,
"opt_type": "convolution",
"opt_params": {
"filter_size": "7",
"num_filter": "128",
"stride": "2"
}
},
"22": {
"opt_id": 22,
"opt_type": "convolution",
"opt_params": {
"filter_size": "7",
"num_filter": "48",
"stride": "1"
}
},
"13": {
"opt_id": 13,
"opt_type": "convolution",
"opt_params": {
"filter_size": "5",
"num_filter": "48",
"stride": "2"
}
},
"26": {
"opt_id": 26,
"opt_type": "convolution",
"opt_params": {
"filter_size": "7",
"num_filter": "96",
"stride": "1"
}
},
"30": {
"opt_id": 30,
"opt_type": "reduction",
"opt_params": {
"reduction_type": "max_pooling",
"pool_size": 2
}
},
"11": {
"opt_id": 11,
"opt_type": "convolution",
"opt_params": {
"filter_size": "5",
"num_filter": "32",
"stride": "2"
}
},
"9": {
"opt_id": 9,
"opt_type": "convolution",
"opt_params": {
"filter_size": "3",
"num_filter": "128",
"stride": "2"
}
}
}
}
该神经网络架构可以可视化为
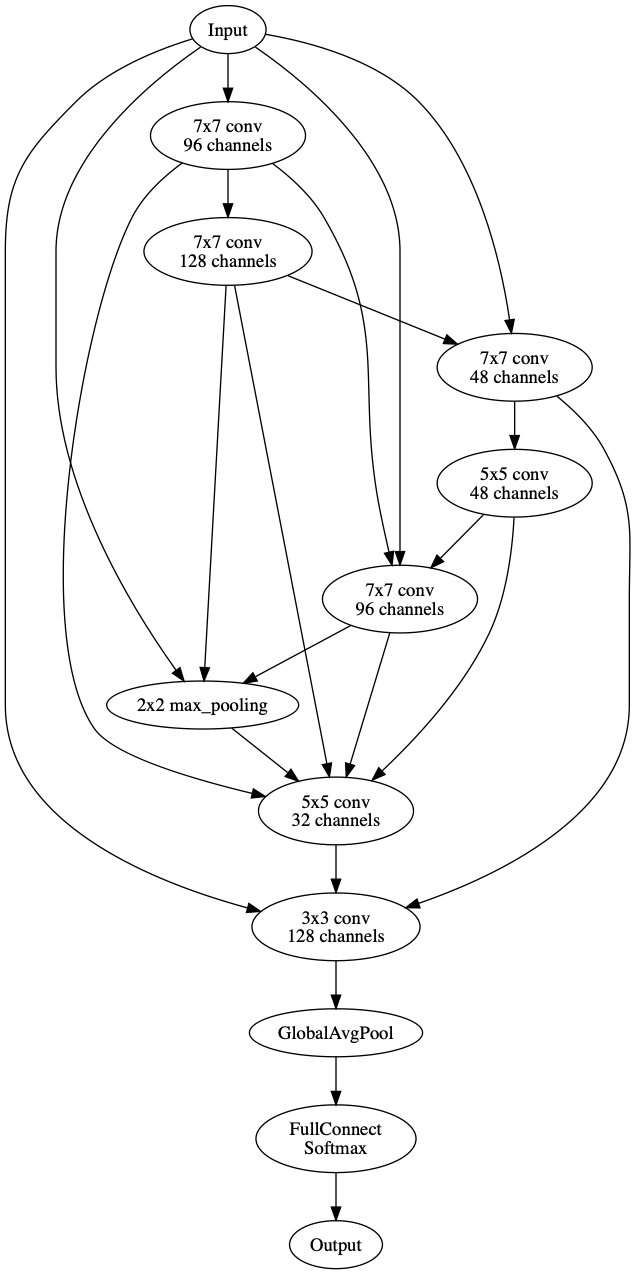
可以在 Katib 中实现以下项目以更好地支持 ENAS
- 添加“微观”模式,即搜索神经单元而不是整个神经网络。
- 添加对循环神经网络的支持,并为 Penn Treebank 任务构建训练容器。
- 如果可能,添加参数共享。
- 将 LSTM 单元从 LSTM.py 中自定义的函数更改为
tf.nn.rnn_cell.LSTMCell - 将 Suggestion 检查点存储到 PVC,以防止意外的 enas 服务 Pod 重启
- 将
RequestCount添加到 API 中,以便 Suggestion 可以清除已完成研究的信息。
可微分架构搜索 (DARTS)
该算法遵循 Hanxiao Liu, Karen Simonyan, Yiming Yang 在 *DARTS: 可微分架构搜索* 中提出的思想:https://arxiv.org/abs/1806.09055。该实现基于官方 GitHub 实现和热门仓库。
该算法通过以可微分的方式描述任务来解决架构搜索的可扩展性挑战。它基于搜索空间中的连续松弛和梯度下降。它能够有效地设计用于图像分类(在 CIFAR-10 和 ImageNet 上)的高性能卷积架构以及用于语言建模(在 Penn Treebank 和 WikiText-2 上)的循环架构。
Katib 实现
为了在当前的 Katib 功能中支持 DARTS,实现方式如下
DARTS Suggestion 服务根据实验搜索空间创建一组基本运算。例如
['separable_convolution_3x3', 'dilated_convolution_3x3', 'dilated_convolution_5x5', 'avg_pooling_3x3', 'max_pooling_3x3', 'skip_connection']Suggestion 将算法设置、层数和基本运算集返回给 Katib Controller
Katib controller 使用适当的设置和所有可能的运算启动DARTS 训练容器。
训练容器运行 DARTS 算法。
指标收集器从训练容器日志中保存 Best Genotype。
Best Genotype 表示
Best Genotype 是每个神经网络层的最佳单元。单元由 DARTS 算法生成。以下是 Best Genotype 的示例
Genotype(
normal=[
[('max_pooling_3x3',0),('max_pooling_3x3',1)],
[('max_pooling_3x3',0),('max_pooling_3x3',1)],
[('max_pooling_3x3',0),('dilated_convolution_3x3',3)],
[('max_pooling_3x3',0),('max_pooling_3x3',1)]
],
normal_concat=range(2,6),
reduce=[
[('dilated_convolution_5x5',1),('separable_convolution_3x3',0)],
[('max_pooling_3x3',2),('dilated_convolution_5x5',1)],
[('dilated_convolution_5x5',3),('dilated_convolution_5x5',2)],
[('dilated_convolution_5x5',3),('dilated_convolution_5x5',4)]
],
reduce_concat=range(2,6)
)
在此示例中,您可以看到 4 个 DARTS 节点,索引分别为:2,3,4,5。
reduce 参数是位于总神经网络层数的 1/3 和 2/3 位置的单元。它们代表缩减单元,其中与输入节点相邻的所有运算步幅都为二。
normal 参数是位于其余神经网络层的单元。它们代表正常单元。
在 CNN 中,所有缩减 (reduce) 和正常 (normal) 中间节点都会被连接,每个节点有 2 条边。
normal 数组中的每个元素都是具有 2 条边的节点。第一个元素是边上的运算,第二个元素是节点索引连接。请注意,索引 0 是 C_{k-2} 节点,索引 1 是 C_{k-1} 节点。
例如,[('max_pooling_3x3',0),('max_pooling_3x3',1)] 意味着 C_{k-2} 节点通过 max_pooling_3x3 运算(滤波器大小为 3 的最大池化)连接到第一个节点,并且 C_{k-1} 节点通过 max_pooling_3x3 运算连接到第一个节点。
reduce 数组与 normal 数组遵循相同的方式。
normal_concat 和 reduce_concat 意味着中间节点之间的连接。
目前,它仅支持在单个 GPU 上运行和二阶近似,这产生了比一阶更好的结果。
可以在 DARTS 中实现以下项目
支持多 GPU 训练。添加选择用于训练的 GPU 的功能。
在 Katib UI 中支持 DARTS。
考虑 Best Genotype 的更好表示方法。
为 CNN 添加更多数据集。目前仅支持 CIFAR-10。
除了 CNN 外,还支持 RNN。
支持微观模式,即搜索特定的神经网络单元。